Sorting data is a common operation when working with pandas. Whether you’re organizing data for display, analysis, or export, sorting helps bring structure and clarity.
In this lesson, we’ll explore 9 sorting use cases, including handling null values, sorting by multiple columns, order direction, and limiting results.
If you want to watch a YouTube video based on this article, we have one uploaded on our YouTube channel. It’s embedded in the article below.
Before we jump into the examples, we have to import in Pandas and NumPy. You won’t need to be an expert in NumPy for this tutorial as we will only be using it to generate null values.
import pandas as pd
import numpy as np
Example 1 - Sort a Series With Integers
Let’s begin with a simple example using a pandas Series made up of integers.
To create a Pandas Series, pass a list of values to pd.Series(): python Copy Edit
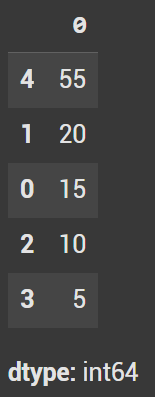
series = pd.Series([15, 20, 10, 5, 55])

By default, when you call .sort_values(), the values are sorted in ascending order — from smallest to largest.
series.sort_values()
The output will start with 5 and end with 55.
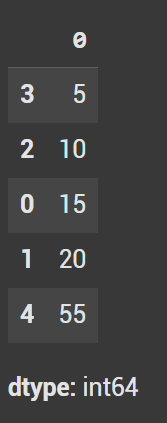
To sort in the opposite direction, use the ascending=False argument:
series.sort_values(ascending=False)
This sorts the series in descending order, putting the largest value (55) first and the smallest (5) last.
Example 2- Sort a DataFrame by a Column of Strings
The remaining examples will focus on sorting DataFrame objects, beginning with sorting a column of strings.
Let’s create a simple DataFrame containing band names and their (hypothetical) average ticket sales:
bands_data = {
"Band": ["Invent Animate", "Silent Planet", "Gojira", "Mastodon", "Architects"],
"Average Ticket Sales": [500, 700, 4000, 4000, 4000] # Hypothetical values
}
df = pd.DataFrame(bands_data)
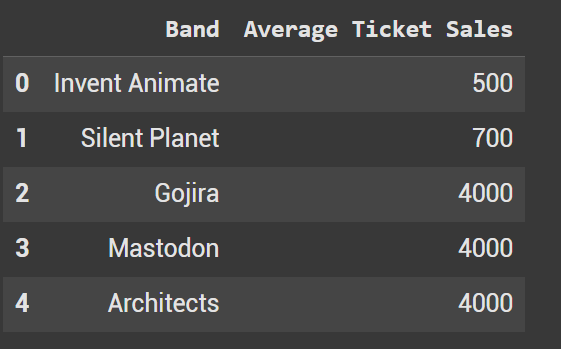
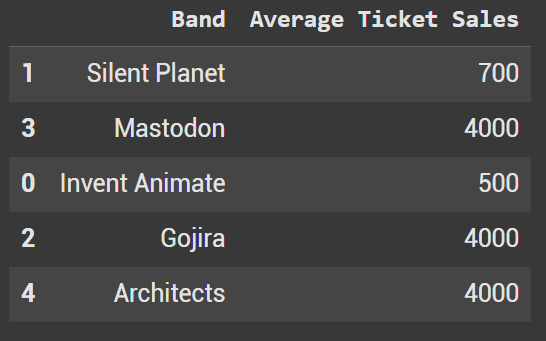
Since we have multiple columns that we can sort by, in sort_values we need to define the exact column. In this case we sort by the band.
Like with the earlier example, it will sort by ascending.
This arranges the rows so that “Architects” comes first (A-Z) and “Silent Planet” last.
df_sorted_bands_asc = df.sort_values(by='Band')
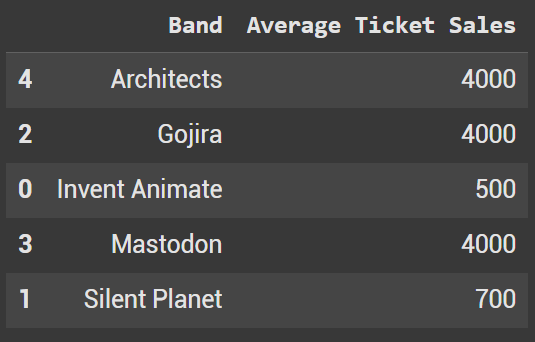
When we set ascending =False, we once again go into descending order. With Strings this means we go from Z to A.
df_sorted_bands_desc = df.sort_values(by='Band', ascending=False)
Example 3 - Sort a DataFrame Based on Two Columns
We also have the capability to sort a dataframe based on two different values. This is pretty important when it comes down to ties. How do we decide which row to populate first?
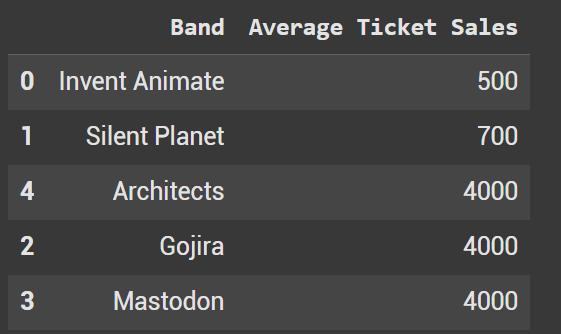
In the Average Ticket Sales column, I have 3 different bands that all have 4000 ticket sales per concert. Let’s sort them.
Instead of a string, for the by = we pass in a list. Put the first column which you want to prioritize in sorting. The 2nd column should be what you use in a tie. Ascending in this example will be true for both columns, although we will change that in a moment.
df_sorted_multi1 = df.sort_values(by=['Average Ticket Sales', 'Band'])
We can define how we want ascending to populate for each column. Pass in a list with the values of True or False. In the code below we want to sort the tickets by descending order and the bands by ascending.
df_sorted_multi2 = df.sort_values(by=['Average Ticket Sales', 'Band'], ascending=[False, True])
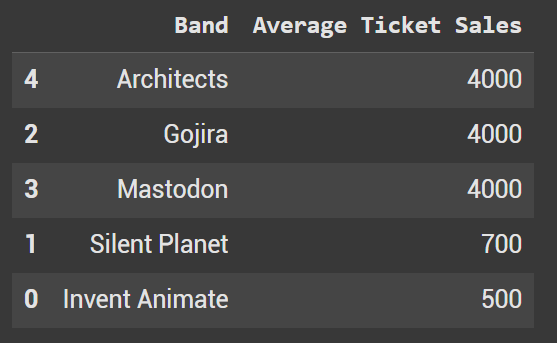
As you can see this prioritizes the bands that have the most sales, and then orders the band names A to Z incase of ties.
Example 4 - Sort in Pandas with Null Values
With real world data, its quite common to deal with null values. A null value is essentially missing data, we have no record of what it should be.
While there are countless ways to deal with missing values in Pandas and to impute their estimated values, let’s look at how we can deal with them when sorting a dataframe.
We are going to expand out the dataframe from the earlier examples and insert in np.nan which will be our null values.
bands_data2 = {
"Band": ["Gojira", "Mastodon", "Architects", "QOTSA", "A Perfect Circle", "Invent Animate", "Silent Planet"],
"Average Ticket Sales": [5000, 4500, 4000, np.nan, np.nan, 500, 700] # QOTSA & A Perfect Circle have NaN
}
df2 = pd.DataFrame(bands_data2)
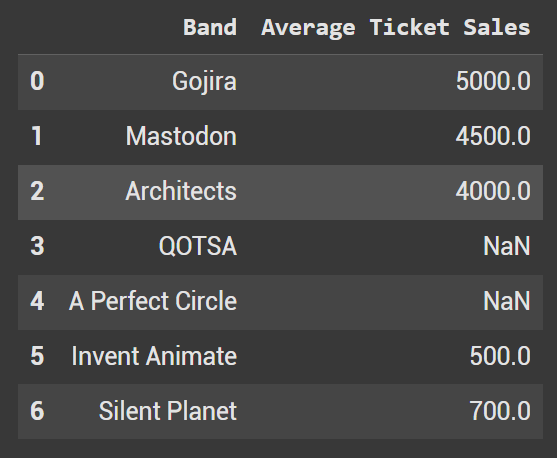
Sort Values allows us to define where we want to store the null values in the resulting order. When na_position = ‘first’, they populate at the top above any values in the dataframe.
df_sorted_nan1 = df2.sort_values(by='Average Ticket Sales', na_position='first')
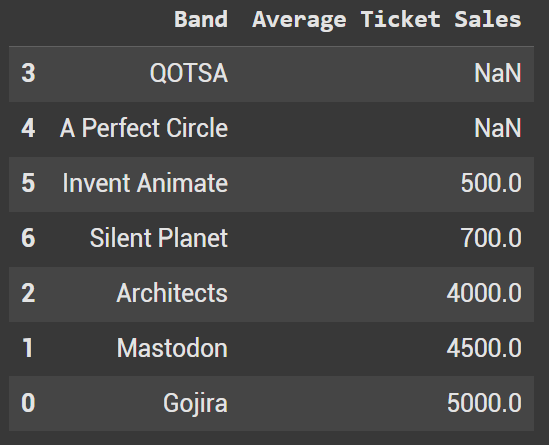
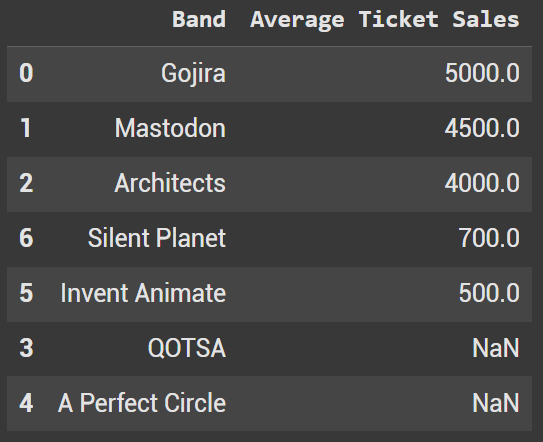
And when na_position=’last’ the values are put at the bottom of the dataframe.
df_sorted_nan2 = df2.sort_values(by='Average Ticket Sales', ascending=False, na_position='last')
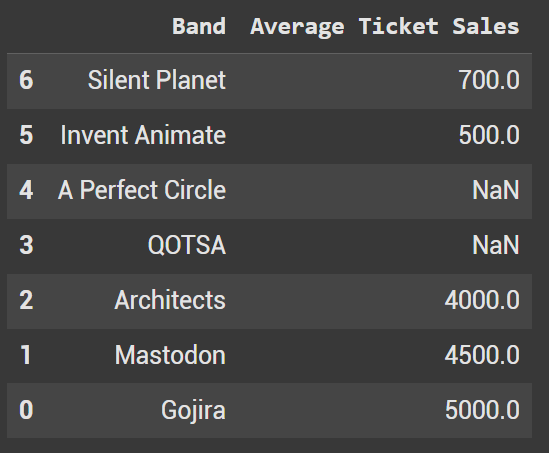
Example 5 - Sort by Index
By default, DataFrame rows are indexed from 0 to n-1. While they’re already in ascending order, the code below demonstrates how to sort by index in descending order
df2.sort_index(ascending=False)
Example 6 - Sort by Index with Date Values
While we’ve covered sorting by numbers and strings, one of the most common and useful cases we haven’t touched yet in Pandas is sorting by dates
With dates, ascending order considers the earliest date first and the latest date last.
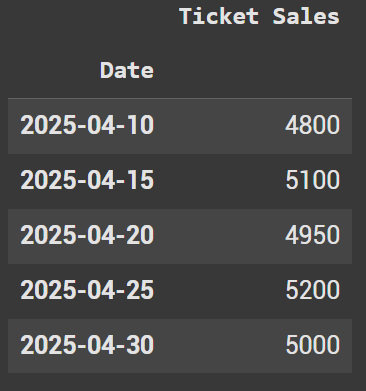
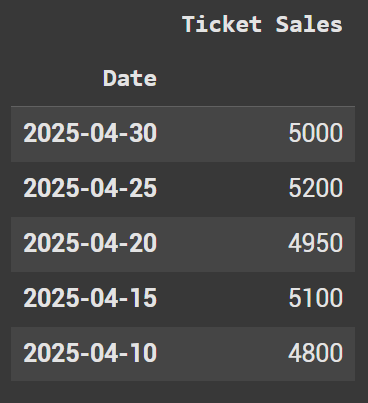
Let’s look at an example where the dates are the index and we have to sort by them. The dataframe down below showcases a bands ticket sales per date.
gojira_sales_data = {
"Date": ["2025-04-10", "2025-04-15", "2025-04-20", "2025-04-25", "2025-04-30"],
"Ticket Sales": [4800, 5100, 4950, 5200, 5000] # Hypothetical sales numbers
}
df_gojira = pd.DataFrame(gojira_sales_data)
df_gojira.set_index("Date", inplace=True)
When sorting with dates, descending order has the latest date first with the earliest date last.
df_gojira.sort_index(ascending=False, inplace = True)
Example 7 - Custom Sorting With Lambda Functions
A more advanced example is sorting with the help of a lambda function.
The lambda function doesn’t alter DataFrame values, but it offers powerful flexibility to customize the sorting order based on your needs
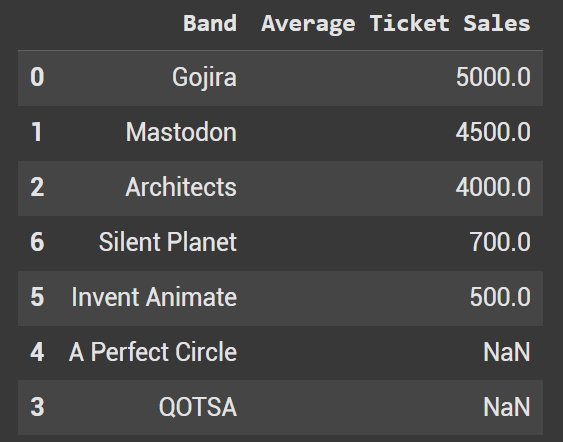
The code below replicates what was shown earlier with null values. We want them at the bottom of the results. The function assigns the value of -1 to any null value. This is technically impossible to achieve with ticket sales, so it guarantees that they are the last rows.
df_sorted_custom = df2.sort_values(by="Average Ticket Sales", key=lambda x: x.fillna(-1), ascending=False)
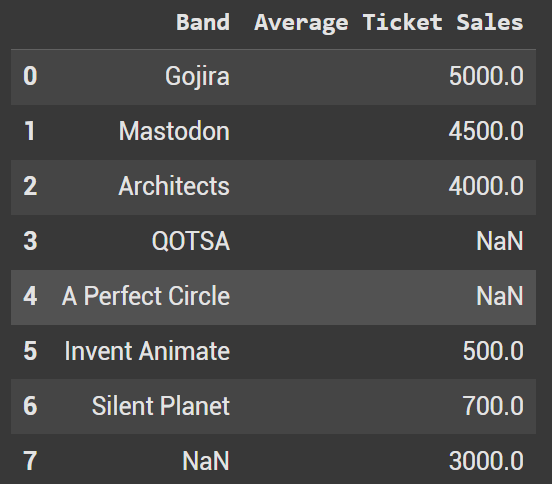
Lambda functions can also impact strings as well. Let’s look at the same use case, but instead of integers we have a null band name.
bands_data3 = {
"Band": ["Gojira", "Mastodon", "Architects", "QOTSA", "A Perfect Circle", "Invent Animate", "Silent Planet", np.nan],
"Average Ticket Sales": [5000, 4500, 4000, np.nan, np.nan, 500, 700, 3000]
}
df3 = pd.DataFrame(bands_data3)
We not fill the null band names with the string zzz. Minus ZZ top, there aren’t many bands that have multiple Zs to start their name.
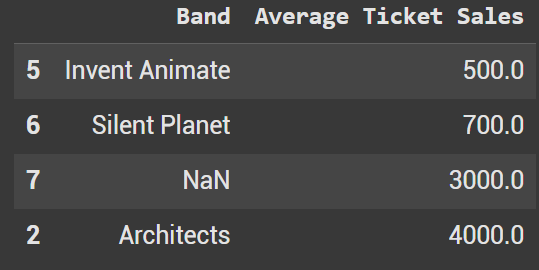
df_sorted_custom2 = df3.sort_values(by="Band", key=lambda x: x.fillna("zzz").str.lower())
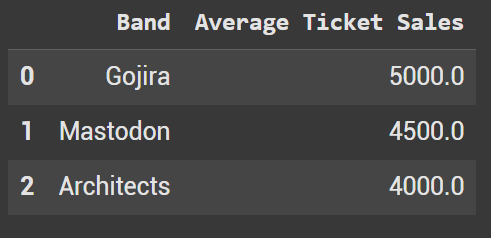
Example 8 - nlargest
By using nlargest, you can quickly filter your DataFrame to show the top X values—no need to sort first and then call .head(X). The code below grabs the 3 largest bands by Average Ticket Sales.
df3.nlargest(3, 'Average Ticket Sales')
Example 9 - nsmallest
By using nsmallest, you can quickly filter your DataFrame to show the bottom X values—no need to sort first and then call .tail(X). The code below grabs the 4 smallest bands by Average Ticket Sales.
df3.nsmallest(4, 'Average Ticket Sales')
Outro
Sorting in pandas is an essential part of data cleaning and analysis. Whether you’re dealing with simple Series, multi-column DataFrames, null values, or custom logic with lambda functions, pandas offers intuitive and powerful tools to help you organize your data efficiently.
By mastering these sorting techniques, you’ll be better equipped to handle real-world data and extract meaningful insights from it.
