The pandas.shift() function is a powerful and versatile tool in data analysis with Python. It allows you to shift the values of a DataFrame or Series up or down along an axis, making it especially useful for comparing a row or column to its previous or future counterpart.
This functionality is commonly applied in time series analysis, feature engineering, and data validation tasks, such as calculating differences or detecting trends over time.
Shift() is also handy for data cleanup. Real-world datasets often come with alignment issues, such as rows being off by one due to logging errors, mismatched timestamps, or corrupted entries. In these cases, shift() can help realign data correctly or isolate problematic rows for further inspection
This tutorial is based on a YouTube video published to our channel. If you want a video walk through check that out.
To start we’re going to import in pandas.
import pandas as pd
We then create a dataframe by passing in a dictionary to pd.DataFrame()
basic = pd.DataFrame({
"NumA": [121,23434,3544,6534,5635,636,7634,834],
"NumB": [15401,124201, 452111,152441,452111, 101451, 254132, 452141],
})
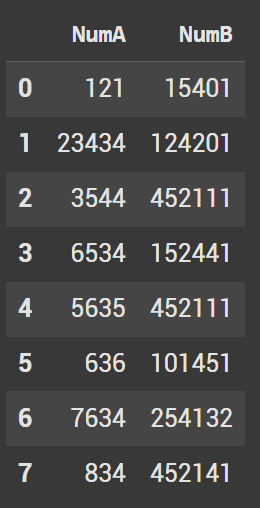
Basic Dataframe Head
Example 1 Shift 1 Row
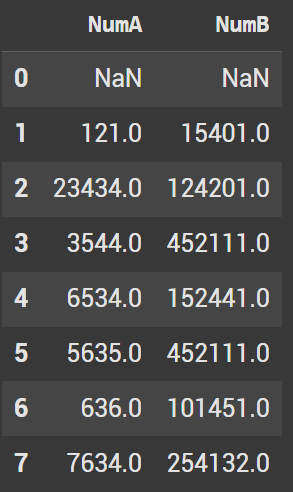
To shift down 1 row, we pass the parameter of 1. This gives our index a value of NaN. The values 121 and 15401 are now in the first index.
basic.head(10).shift(1)
Example 2 Shift 2 Rows
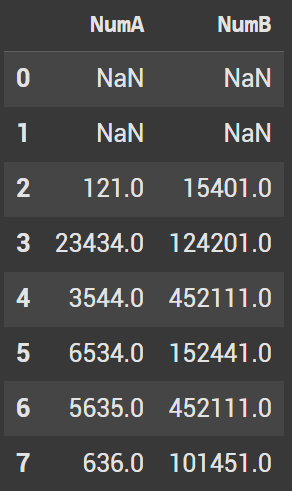
To shift down 2 rows, we pass the parameter of 2. Now the zero and one index have null values.
basic.head(10).shift(2)
Example 3 Shift Backwards
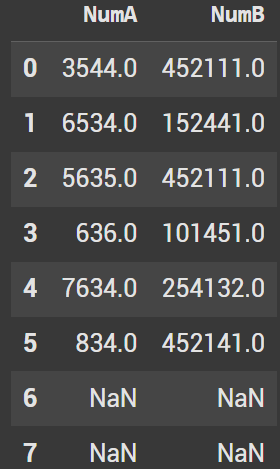
To shift in the opposite direction, we invert the number passed. This causes the last two rows in the dataframe to have missing values.
basic.head(10).shift(-2)
Example 4 How to fill values
Often when shifting, you’ll encounter null values. These values will show up as NaN in your dataframe. This is the default when using shift.
To fill these in, use the parameter fill_value = YOUR_VALUE. Your Value is what you want inserted instead of a null value.
In the code below we pass in the fill value of 0. The first two rows now have a 0 instead of NaN.
basic.head(10).shift(2, fill_value=0)
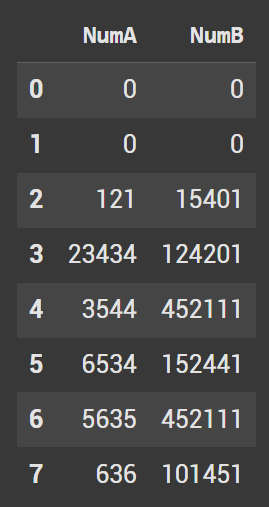
Example 5 Shift to the right
By default (and most of the time you’ll be using shift) shift looks at the row above or below. If you set the axis=1 as a parameter, you can look at columns.
This now causes the NumA column to have all null values. NumB inherits the values in NumA. The old values in NumB do not show up in this new shift.
basic.head(10).shift(1, axis = 1)
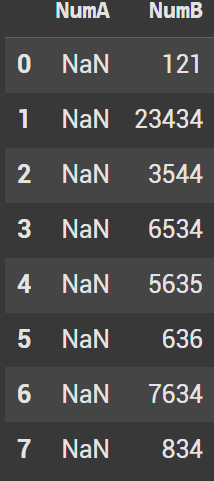
Example 6 Shift to the Left
Inversing the number will have the same impact as when we looked at reversing the rows above. The values move left this time instead of right.
basic.head(10).shift(-1, axis = 1)
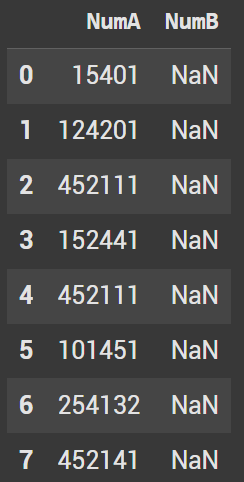
Coding Interview Example
Let’s take a look at an example of how this can be used within a coding interview as it’s a quite common question.
Question: Find transactions where person paid more than last time. In the final dataframe get the previous and next transactions as well.
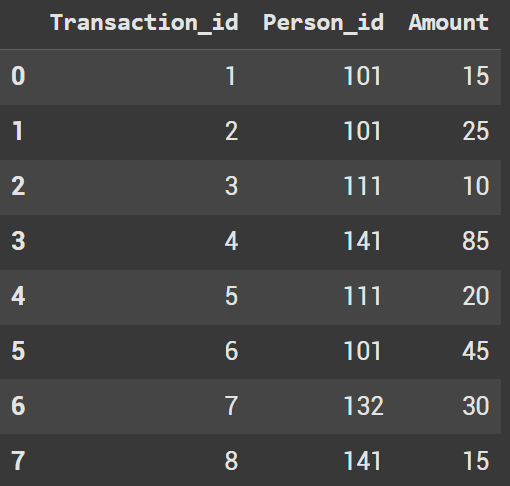
df = pd.DataFrame({
"Transaction_id": [1,2,3,4,5,6,7,8],
"Person_id": [101,101, 111,141,111, 101, 132, 141],
"Amount": [15, 25, 10, 85, 20, 45, 30, 15]
})
Let’s use the dataframe from above to answer this question.
Let’s first sort the dataframe by the Person_id
df = df.sort_values('Person_id', ascending = True)
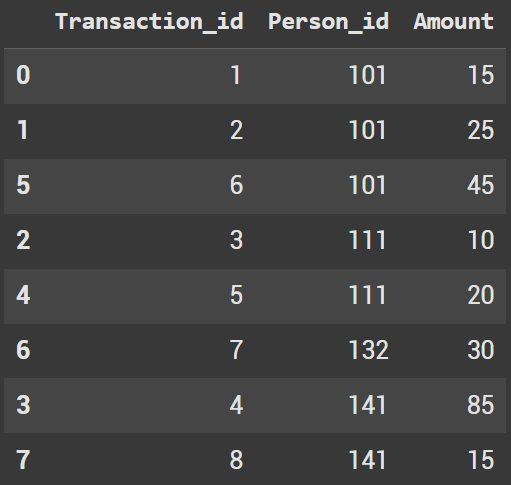
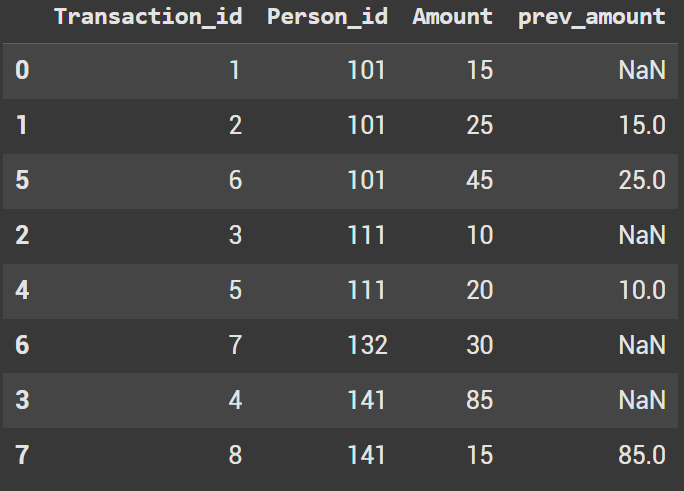
Next we will groupby the person_id and shift the amount by 1 row
df['prev_amount'] = df.groupby('Person_id')['Amount'].shift(1)
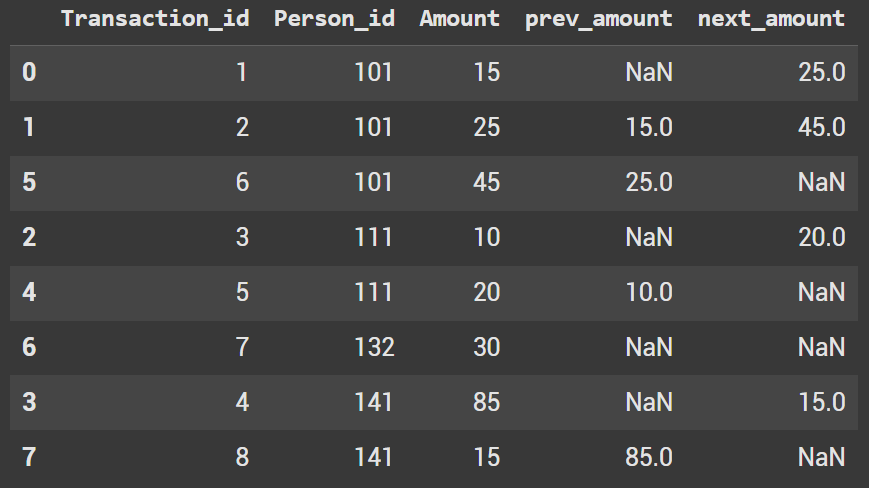
If you want to replicate this for the other direction, repeat the code. The only difference will be the -1 value.
df['next_amount'] = df.groupby('Person_id')['Amount'].shift(-1)
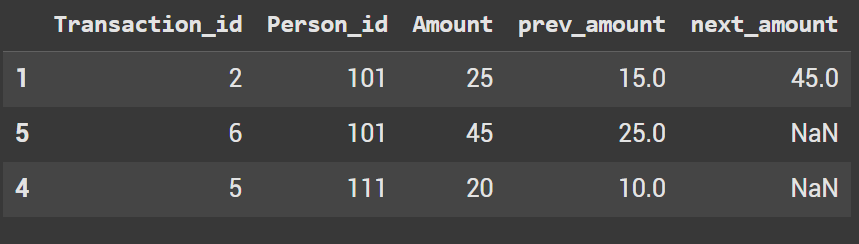
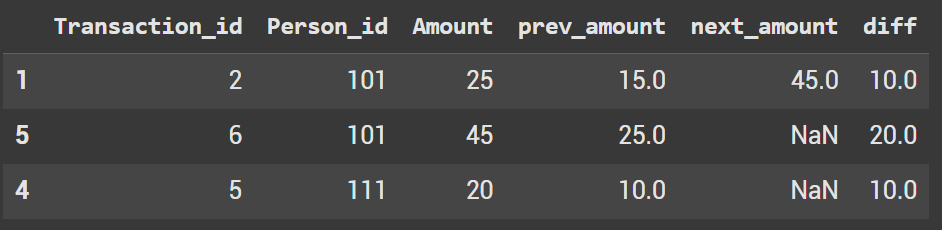
We only care about the instance where the amount is greater than the previous amount, so filter the dataframe on that. Let’s use query (although it’s simple to do with loc)
df.query('Amount > prev_amount')
Lastly, we find the difference by creating a new column and taking amount – prev amount.
df['diff'] = df['Amount'] - df['prev_amount']
df.query('Amount > prev_amount')
Conclusion
Those were 7 different examples of how you can use Pandas Shift() to move a dataframe left, right, down, and up. Thank you for checking out this article!
