Welcome! This article is the first in a new series that will look at Retrieval-Augmented Generation (RAG), which is one of the best ways to combine external information with large language models (LLMs).
we’ll dive into the foundation of RAG pipelines: the embedding model. Specifically, we’ll explore SBERT (Sentence-BERT)
What Is RAG? A Quick Overview
Before focusing on embeddings, let’s quickly recap what a RAG pipeline is.
At its core, RAG combines two key ideas:
Retrieval: Fetch relevant documents or passages from a knowledge base using vector similarity.
Generation: Feed the retrieved context into a language model to generate a final, contextually accurate answer.
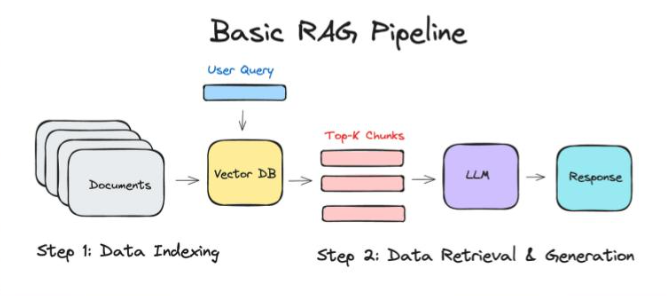
Here’s a simplified flow:
Knowledge Base: A collection of documents stored as vector embeddings.
User Query: The user asks a question.
Vector Database Lookup: The system finds the top K most similar document chunks based on semantic similarity.
Response Generation: These top documents are passed into the LLM, which generates a well-informed answer.
The embedding model powers that crucial middle step , identifying which pieces of text are most relevant to the user’s query.
What most RAG pipelines look like
Introducing SBERT (Sentence-BERT)
Sbert: Sentence-BERT is a modification of Bert model, designed to generate fixed length vector representations of sentences. It enables efficient sematic similarity comparison, clustering and search.
SBERT takes full sentences into account, providing a more comprehensive understanding of the text semantics
SBERT is the go to Python module for accessing, using and training state-of-the-art embedding and reranker models.
It can be used to compute embeddings using Sentence Transformer models, to calculate similarity scores using Cross-Encoder (a.k.a. reranker) models , or to generate sparse embeddings using Sparse Encoder models.
This unlocks a wide range of applications, including semantic search, semantic textual similarity, and paraphrase mining.
Why SBERT?
While there are many options for embeddings (e.g., OpenAI’s text-embedding-3-small, or models from Jina AI), SBERT offers several key advantages:
Lightweight and cost-efficient: It can run locally, avoiding per-API costs.
Open-source and fine-tunable: You can tailor it to your domain (legal, medical, etc.).
Flexible: Supports multiple model sizes and architectures.
Proven performance: Strong semantic understanding for general-purpose text.
One of the most popular base models is all-MiniLM-L6-v2, which offers a great balance between speed and accuracy.
Basic Example of Embeddings using sentence-transformers
To understand SBERT, you first need to understand what embeddings are.
Computers don’t inherently understand text , they understand numbers. So, we convert (or encode) text into vectors , lists of numbers that represent the meaning of the text in a high-dimensional space.
we start by installing sentence-transformers
!pip install -U sentence-transformers
Next, from sentence-transformers, we import SentenceTransformer
Note: SentenceTransformer is a Python library that uses pretrained transformer models (e.g BERT) to generate semantic vector embeddings for sentences, paragraphs, or documents, useful for tasks like similarity search and clustering.
Next, we load a pretrained Sentence Transformer model e.g (all-MiniLM-L6-v2)
from sentence_transformers import SentenceTransformer
sbert_model = SentenceTransformer('all-MiniLM-L6-v2')
Next, we create a list of sentence to encode
sentences = [
"The weather is lovely today.",
"It's so sunny outside!",
"He drove to the stadium.",
]
sentence_embeddings = sbert_model.encode(sentences)
print(sentence_embeddings.shape)
After encoding, we can measure how close these vectors are
similarities = sbert_model.similarity(sentence_embeddings, sentence_embeddings)
print(similarities)
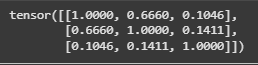
| Sentence | 1 | 2 | 3 |
|---|---|---|---|
| 1. The weather is lovely today. | 1.00 | 0.66 | 0.10 |
| 2. It’s so sunny outside. | 0.66 | 1.00 | 0.14 |
| 3. He drove to the stadium. | 0.10 | 0.14 | 1.00 |
This table shows that sentences (1) and (2) are semantically close (0.66), while (1) and (3) are not (0.10).
SBERT in a Simple RAG Example
Let’s walk through a small example to demonstrate how SBERT fits into a RAG-style retrieval process.
!pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer, util
import openai
import numpy as np
knowledge = [
"The capital of France is Paris.",
"The Eiffel Tower is one of the most famous landmarks in Paris.",
"Albert Einstein developed the theory of relativity.",
"Python is a popular programming language.",
"The Mona Lisa was painted by Leonardo da Vinci.",
]
model = SentenceTransformer('all-MiniLM-L6-v2')
knowledge_embeddings = model.encode(knowledge, convert_to_tensor=True)
user_query = "Who painted the Mona Lisa?"
query_embedding = model.encode(user_query, convert_to_tensor=True)
Next we compute Similarity Scores.
This code finds the top 3 most similar embeddings to a query by computing cosine similarities between the query and all knowledge embeddings, then selecting the indices of the highest scores.
The system ranks all knowledge base entries by similarity. The top match here is:
“The Mona Lisa was painted by Leonardo da Vinci.” (Similarity: 0.88)
That similarity score (0.88) is quite high, meaning the model is confident these sentences are semantically related.
Even without calling an LLM, we can see how embeddings help identify the most relevant context for a question.
cos_scores = util.pytorch_cos_sim(query_embedding, knowledge_embeddings)[0]
top_k = min(3, len(knowledge))
top_results = np.argpartition(-cos_scores, range(top_k))[0:top_k]
print("Query:", user_query)
print("\nTop Matching Knowledge Pieces:")
for idx in top_results:
print(f"- {knowledge[idx]} (score: {cos_scores[idx]:.4f})")

retrieved_context = "\n".join([knowledge[idx] for idx in top_results])
response = client.chat.completions.create(
model="gpt-4.1",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": f"Context:\n{retrieved_context}\n\nQuestion: {user_query}\nAnswer in JSON:"
}
]
}
],
response_format={
"type": "json_object"
},
temperature=0,
max_completion_tokens=2048,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
store=False,
)
Cross Encoders: For Re-Ranking
SBERT can also function in a cross-encoder configuration, often used for re-ranking.
While embedding models compute similarity independently (each sentence is encoded separately), cross-encoders take both texts together and directly predict a similarity score.
This makes them more accurate but also much slower, so they’re typically used after the initial retrieval to re-rank the top 10–20 results.
Characteristics of Cross Encoder (a.k.a reranker) models:
- Calculates a similarity score given pairs of texts.
- Generally provides superior performance compared to a Sentence Transformer (a.k.a. bi-encoder) model.
- Often slower than a Sentence Transformer model, as it requires computation for each pair rather than each text.
- Due to the previous 2 characteristics, Cross Encoders are often used to re-rank the top-k results from a Sentence Transformer model.
from sentence_transformers.cross_encoder import CrossEncoder
model = CrossEncoder("cross-encoder/stsb-distilroberta-base")
query = "A man is eating pasta."
corpus = [
"A man is eating food.",
"A man is eating a piece of bread.",
"The girl is carrying a baby.",
"A man is riding a horse.",
"A woman is playing violin.",
"Two men pushed carts through the woods.",
"A man is riding a white horse on an enclosed ground.",
"A monkey is playing drums.",
"A cheetah is running behind its prey.",
]
ranks = model.rank(query, corpus)
print("Query: ", query)
for rank in ranks:
print(f"{rank['score']:.2f}\t{corpus[rank['corpus_id']]}")
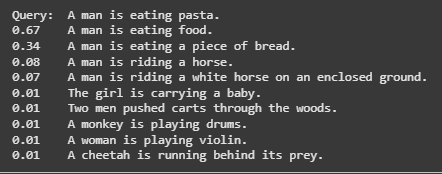
Cross-encoders are especially helpful for domain-specific RAG systems, such as legal or medical applications, where nuanced language can confuse standard embedding models.
Sparse Encoder
SBERT also supports sparse encoders, which are optimized for large-scale retrieval systems. These encoders use sparse vector representations (similar to TF-IDF or BM25) but retain the semantic advantages of transformer models. They’re often used in hybrid retrieval setups, combining dense (semantic) and sparse (keyword-based) search methods
Characteristics of Sparse Encoder models:
- Calculates sparse vector representations where most dimensions are zero.
- Provides efficiency benefits for large-scale retrieval systems due to the sparse nature of embeddings.
- Often more interpretable than dense embeddings, with non-zero dimensions corresponding to specific tokens.
- Complementary to dense embeddings, enabling hybrid search systems that combine the strengths of both approaches.
- The usage for Sparse Encoder models follows a similar pattern to Sentence Transformers:
from sentence_transformers import SparseEncoder
# Load a pretrained SparseEncoder model
model = SparseEncoder("naver/splade-cocondenser-ensembledistil")
# The sentences to encode
sentences = [
"The weather is bad today.",
"It's rainy outside!",
"He drove to the airport.",
]
# Calculate sparse embeddings by calling model.encode()
embeddings = model.encode(sentences)
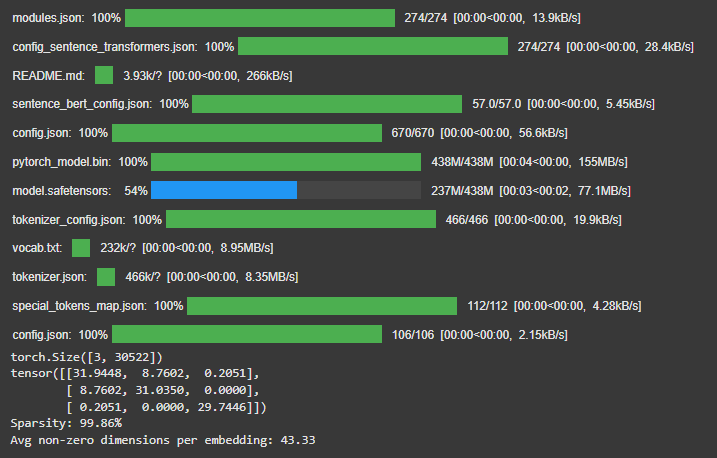
print(embeddings.shape)
# [3, 30522] - sparse representation with vocabulary size dimensions
# Calculate the embedding similarities (using dot product by default)
similarities = model.similarity(embeddings, embeddings)
print(similarities)
# Check sparsity statistics
stats = SparseEncoder.sparsity(embeddings)
print(f"Sparsity: {stats['sparsity_ratio']:.2%}") # Typically >99% zeros
print(f"Avg non-zero dimensions per embedding: {stats['active_dims']:.2f}")
Final thought
SBERT (Sentence-BERT) is one of the most important building blocks in modern Retrieval-Augmented Generation systems. It powers the retrieval process by:
Converting text into embeddings,
Measuring semantic similarity,
Helping LLMs access the most relevant information.
By understanding how SBERT works , and when to enhance it with cross-encoders or fine-tuning , you can design more efficient, accurate, and domain-optimized RAG pipelines.
Stay tuned for the next article in this series, where we’ll explore how to fine-tune SBERT for your own data and improve retrieval accuracy in specialized domains.
