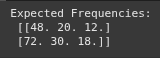
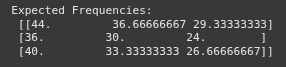

https://youtu.be/aeUy6B2jKJI Example 1 - Manual Calculation - Strikeouts Per Season Example 2 Scipy Example 3 Marathon Times Example viz
In Python, a quantile is a statistical term used to describe a point or value below which a certain proportion of the...
https://youtu.be/p4H2b2x_nWc#population and sample variance/std deviationVariance measures how far each data point in the set is from the mean andthus from every other...
We are going to be looking at Python Z-score. Z-score tells us how far a data poin is from the mean. https://youtu.be/QjG1ljFNF9U...
Spearman Rank Correlation [Simply explained] https://youtu.be/TNQTd9gR1c0 Example 2 Fast wth scipy