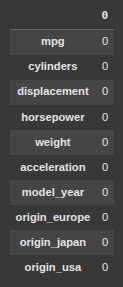
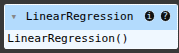
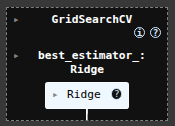
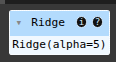
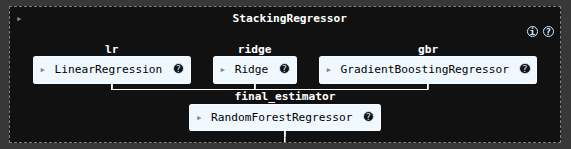
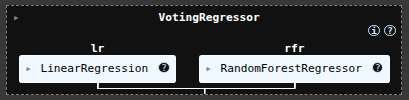
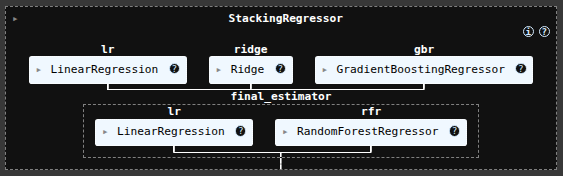
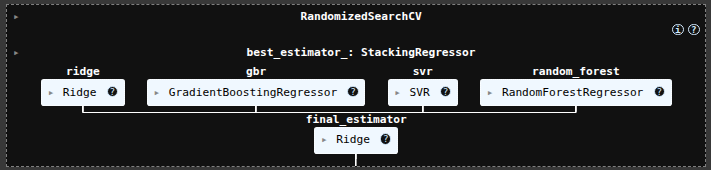
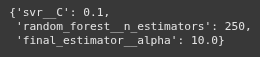
scikit-learn Stacking Regressor June 3, 2025 Ryan Nolan No comments yet import pandas as pd import numpy as np import seaborn as sns sns.get_dataset_names() mpg = sns.load_dataset("mpg") mpg mpg = mpg.drop('name', axis=1) mpg = pd.get_dummies(mpg) mpg.head(10) SEE ALL NULL VLAUES pd.DataFrame(mpg.isnull().sum().sort_values(ascending=False)) mpg['horsepower'].fillna(mpg['horsepower'].mean(), inplace=True) pd.DataFrame(mpg.isnull().sum().sort_values(ascending=False)) X = mpg.drop('mpg', axis=1) y = mpg['mpg'] from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19) from sklearn.linear_model import LinearRegression lr = LinearRegression() lr.fit(X_train, y_train) y_pred = lr.predict(X_test) from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score mean_squared_error(y_test, y_pred) from sklearn.ensemble import RandomForestRegressor rfr = RandomForestRegressor(random_state=13) rfr.fit(X_train, y_train) y_pred = rfr.predict(X_test) mean_squared_error(y_test, y_pred) from sklearn.linear_model import Ridge ridge = Ridge() param_grid = { 'alpha': [0.05, 0.1, 0.3, 1, 3, 5, 10, 15, 30, 50, 75], } from sklearn.model_selection import GridSearchCV ridge_cv = GridSearchCV(estimator=ridge, param_grid=param_grid, cv=5, scoring='neg_mean_squared_error', n_jobs=-1) ridge_cv.fit(X_train, y_train) ridge_cv.best_estimator_ mean_squared_error(y_test, y_pred) from sklearn.ensemble import GradientBoostingRegressor gbr = GradientBoostingRegressor() gbr.fit(X_train, y_train) y_pred = gbr.predict(X_test) mean_squared_error(y_test, y_pred) from sklearn.ensemble import StackingRegressor estimators = [ ('lr', lr), ('ridge', ridge_cv.best_estimator_), ('gbr', gbr), ] sr = StackingRegressor( estimators=estimators, final_estimator=rfr ) sr.fit(X_train, y_train) y_pred = sr.predict(X_test) mean_squared_error(y_test, y_pred) voting classifier from sklearn.ensemble import VotingRegressor vc = VotingRegressor([('lr', lr), ('rfr', rfr), ], weights=[1,2]) vc.fit(X_train, y_train) y_pred = vc.predict(X_test) mean_squared_error(y_test, y_pred) sr2 = StackingRegressor( estimators=estimators, final_estimator=vc ) sr2.fit(X_train, y_train) y_pred = sr2.predict(X_test) mean_squared_error(y_test, y_pred) hyperparamater tuning from sklearn.svm import SVR base_regressors = [ ('ridge', ridge_cv.best_estimator_), ('gbr', gbr), ('svr', SVR(C=1.0, kernel='linear')), ('random_forest', RandomForestRegressor()), ] stacking_regressor = StackingRegressor( estimators=base_regressors, final_estimator=Ridge(alpha=1.0) ) param_grid = { 'random_forest__n_estimators': [50, 100, 250], 'svr__C': [0.1, 1.0, 10.0], 'final_estimator__alpha': [0.1, 1.0, 10.0], } from sklearn.model_selection import RandomizedSearchCV random_search = RandomizedSearchCV(stacking_regressor, param_grid, n_iter=10, cv=3, scoring='neg_mean_squared_error', n_jobs=-1) random_search.fit(X_train, y_train) y_pred = random_search.predict(X_test) mean_squared_error(y_test, y_pred) random_search.best_params_ Ryan Nolan Ryan is a Data Scientist at a fintech company, where he focuses on fraud prevention in underwriting and risk. Before that, he worked as a Data Analyst at a tax software company. He holds a degree in Electrical Engineering from UCF. Post navigation PreviousNext Leave a Reply Cancel replyYour email address will not be published. Required fields are marked *Comment * Name * Email * Website Save my name, email, and website in this browser for the next time I comment. Δ