import requests
import pandas as pd
from bs4 import BeautifulSoup
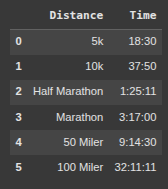
Basic Example HTML Code -> Runners
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Personal Running Bests</title>
</head>
<body>
<h1>Personal Running Bests</h1>
<table>
<thead>
<tr>
<th>Distance</th>
<th>Time</th>
</tr>
</thead>
<tbody>
<tr>
<td>5k</td>
<td>18:30</td>
</tr>
<tr>
<td>10k</td>
<td>37:50</td>
</tr>
<tr>
<td>Half Marathon</td>
<td>1:25:11</td>
</tr>
<tr>
<td>Marathon</td>
<td>3:17:00</td>
</tr>
<tr>
<td>50 Miler</td>
<td>9:14:30</td>
</tr>
<tr>
<td>100 Miler</td>
<td>32:11:11</td>
</tr>
</tbody>
</table>
</body>
</html>
"""
Extract headers
headers = [th.get_text(strip=True) for th in table.find_all("th")]
headers
Step 5: Extract table rows
rows = []
for tr in table.find_all("tr")[1:]: # Skip header row
cells = [td.get_text(strip=True) for td in tr.find_all("td")]
if cells:
rows.append(cells)
# Step 6: Create a pandas DataFrame
df = pd.DataFrame(rows, columns=headers)
df
Example 2 Metallica Ticket Sales
url = "https://en.wikipedia.org/wiki/WorldWired_Tour"
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, "html.parser")
Only Grab the First Table We don't want that in this instance
table = soup.find("table")
table

Grab All Tables. We don't want that in this instance, we need to target a specific table
# or find all tables
tables = soup.find_all("table")
tables
Target a specific table #TO DO -> 2017 Concert
table = None
for th in soup.find_all("th"):
if "Date (2017)" in th.get_text():
table = th.find_parent("table")
break
table
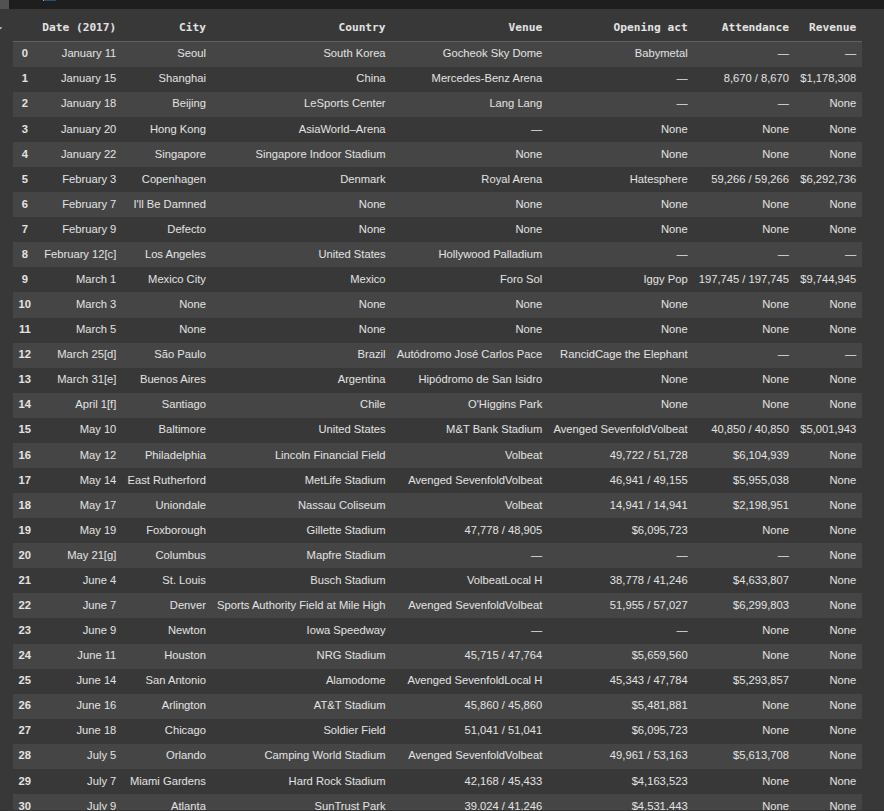
headers = [th.get_text(strip=True) for th in table.find('tr').find_all('th')]
for tr in table.find_all('tr')[1:]: # Skip header row
cells = tr.find_all(['th', 'td'])
row = [cell.get_text(strip=True).replace('\xa0', ' ') for cell in cells]
rows.append(row)
df = pd.DataFrame(rows, columns=headers[:len(rows[0])]) # Avoid header mismatch
df
Cleaning up data, tons of ways we can start cleaning up date, some sites super easy and nice tables, this one isnt the best, should have multiple support columns etc
rename date column
df.rename(columns={'Date (2017)': 'date'}, inplace=True)
remove [] in date column
df['date'] = df['date'].str.replace(r'\[.*?\]', '', regex=True).str.strip()
df
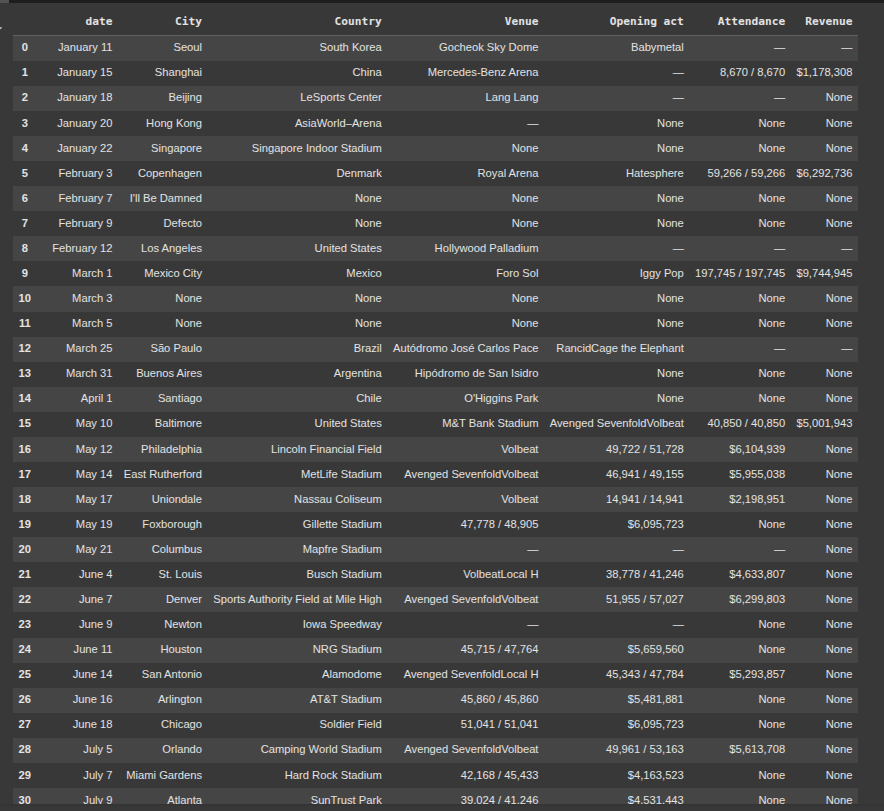
forward fill to fix city, venue, and country issue
df['City'] = df['City'].ffill()
df['Country'] = df['Country'].ffill()
df['Venue'] = df['Venue'].ffill()
df
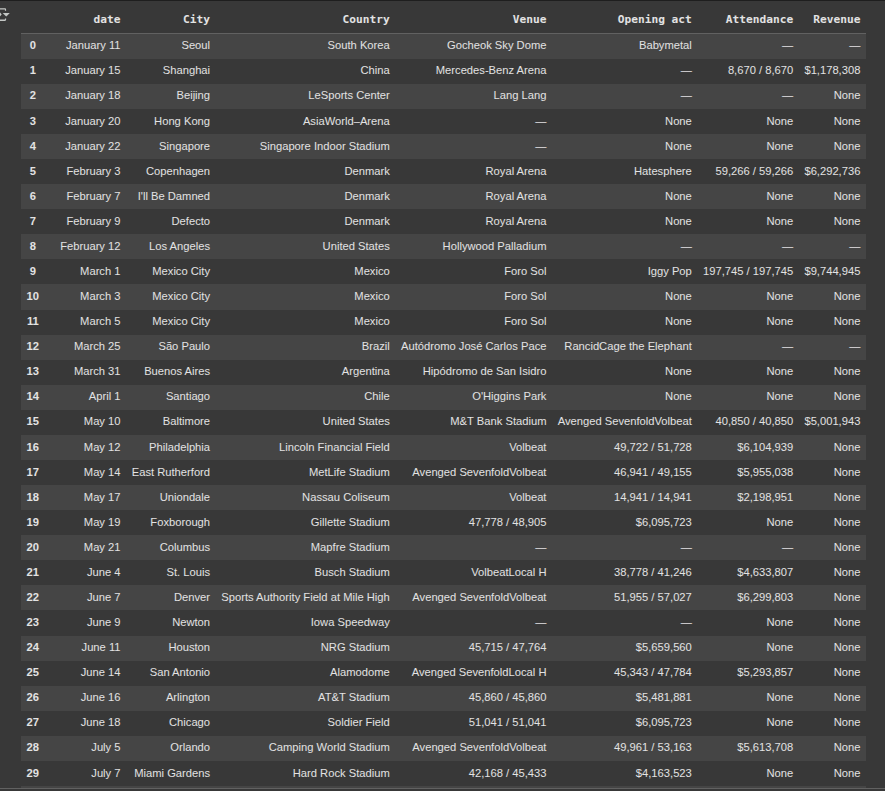
fix column names
df.columns = df.columns.str.strip()
df.columns = df.columns.str.replace(' ', '_')
df.columns = df.columns.str.lower()
df
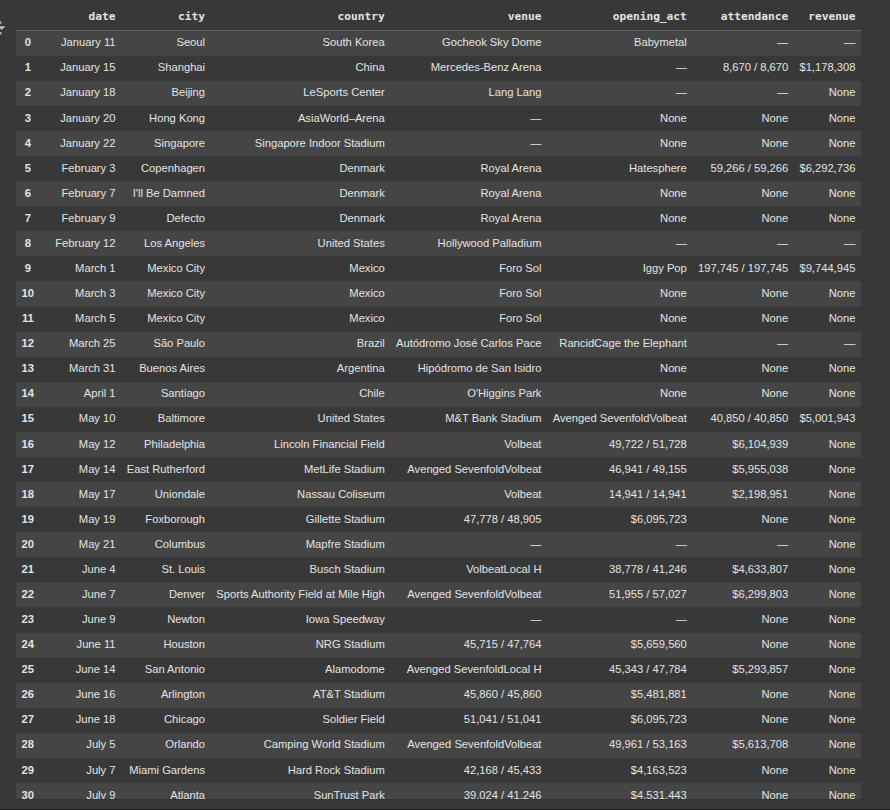
Fix attendance issue
def is_attendance(val):
if pd.isna(val):
return False
pattern = r'^\d{1,3}(?:,\d{3})? ?/ ?\d{1,3}(?:,\d{3})?$'
return bool(pd.Series(val).str.contains(pattern, regex=True)[0])
df
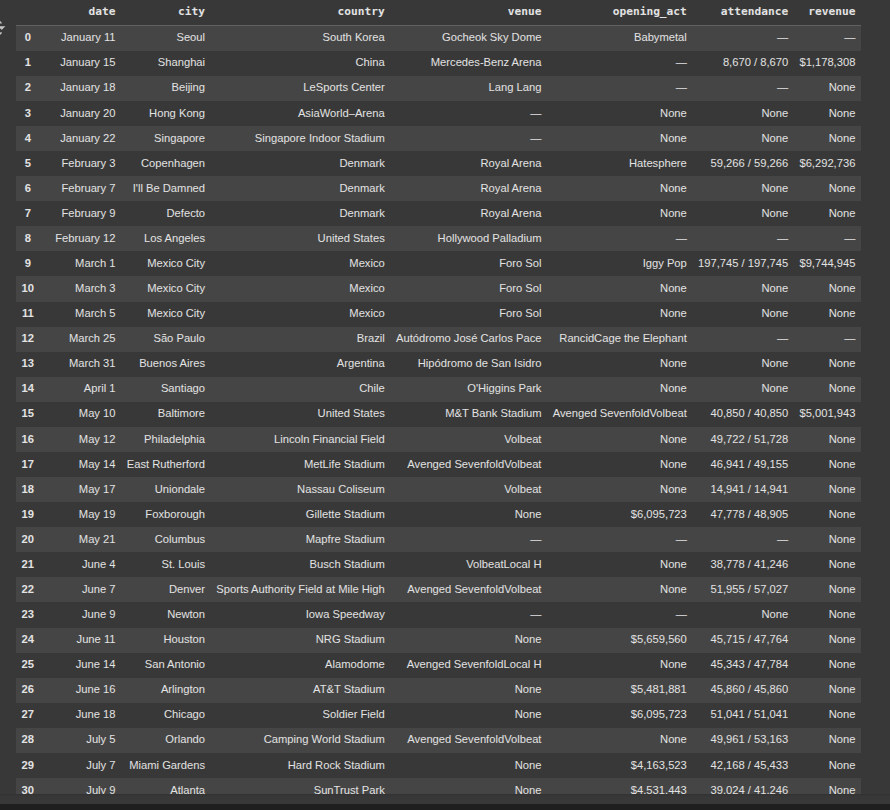
Fix stadium issue
venue_keywords = r'\b(?:Arena|Center|Field|Stadium|Garden|Park|Speedway)\b'
mask = df['country'].str.contains(venue_keywords, case=False, na=False)
df.loc[mask, 'venue'] = df.loc[mask, 'country']
df.loc[mask, 'country'] = None # Clear them from 'country'
df
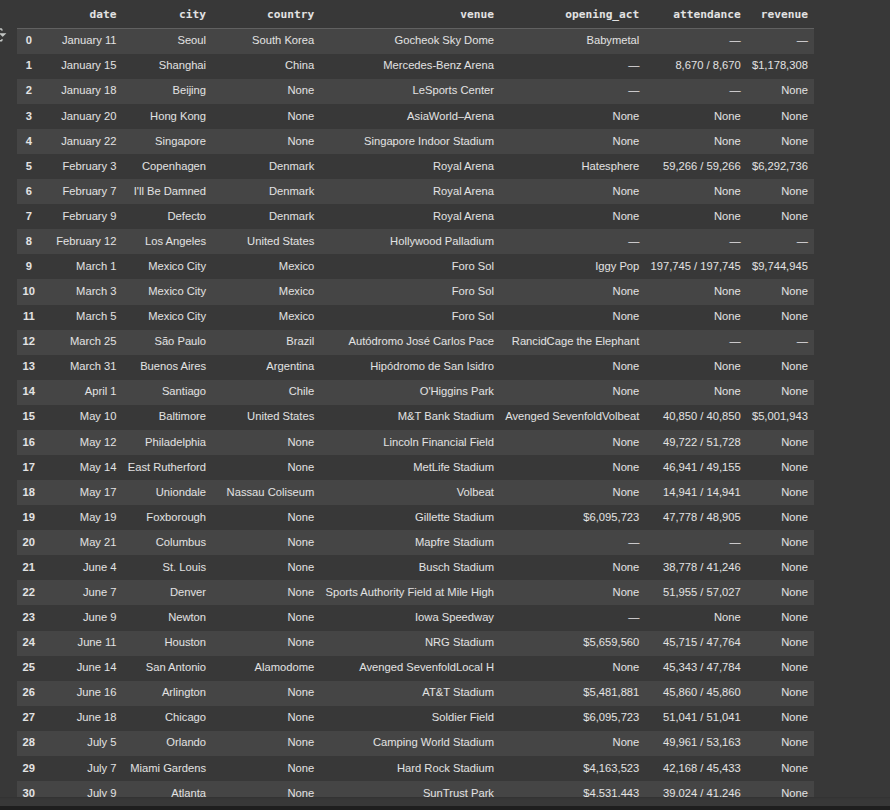
Export to CSV
df.to_csv("metallica.csv", index=False)
