One of the best benefits of using N8N is the ability to integrate in APIs like that of Apify with ease. In just a few nodes we can scrape LinkedIn (a site which is very hard to scrape) and send data into a Google Sheet. Integrations like this often save sales teams hours each week and get them accurate data within one or more different workflows.
This lesson will walk you through how you can scrape company data. The workflow presented was originally built for a Machine Learning software company that was looking for LinkedIn leads in a certain vertical.
If you are brand new to N8N you can sign up here
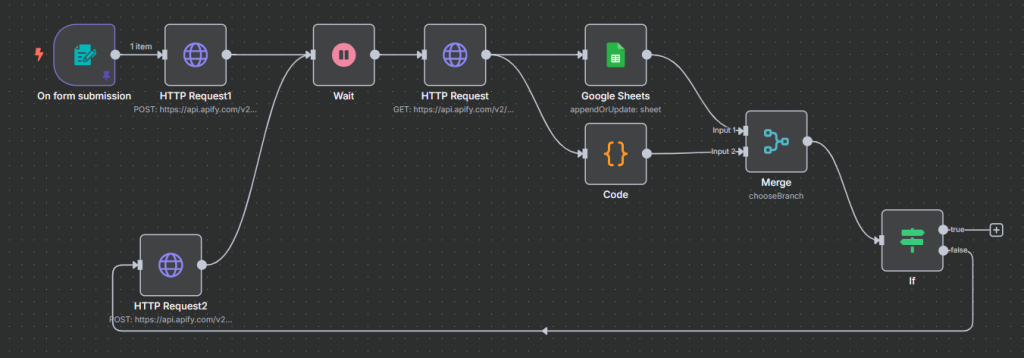
Essentially the workflow starts with a company URL and goes and finds X similar companies while getting information like size, industry, contacts and more. At the end it outputs all the results into Google Sheets. We also filter out any duplicates!
Embedded below is the video uploaded to our YouTube channel, so feel free to watch that instead of reading the article.
In addition, if you are looking for any Data or N8N help, reach out to us here. We are taking on new customers.
Let’s get started on this lesson
Form Submission
To start we’re going to create a simple form that inputs in a Company URL.
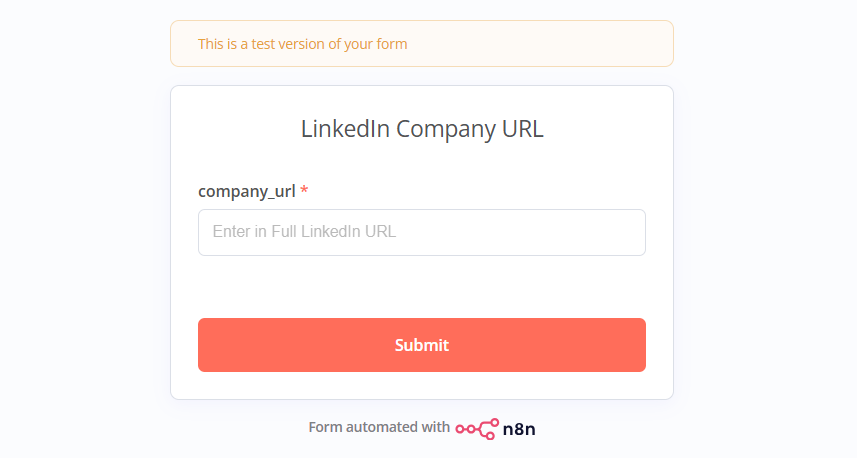
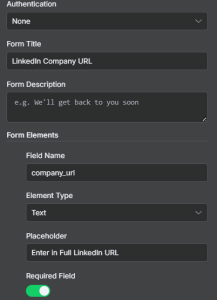
Set up a trigger node for On Form Submission. In the popup fill out the form title with: LinkedIn Company URL.
Add a Form element for the company url by setting the field name to company_url, setting the type to text and writing placeholder text. Make this a required field.
Apify Component
The hardest part of this workflow was finding the exact scraper I needed. Most Apify LinkedIn scrapers didn’t include similar companies. This one however did: LinkedIn Scraper I used
Setting this up will take the next 3 sports. Essentially what we need to do is
- HTTP Post Request
- Wait (So the Data is Populated)
- HTTP Get Request
I’ll break them down below, but to get the Post and Get requests, you will have to navigate to the API dropdown and click endpoints.
HTTP Post Request
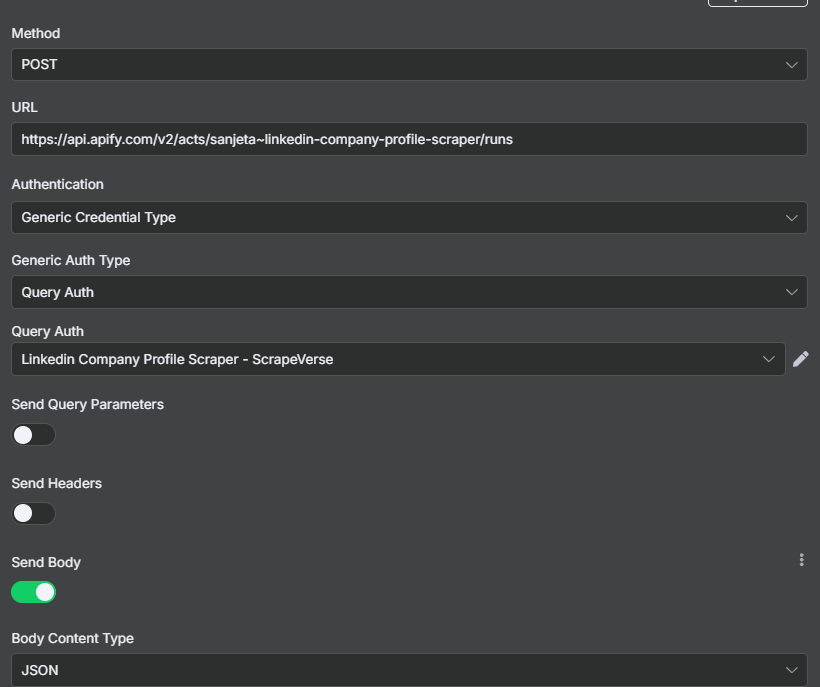
Select the HTTP Request node and choose POST. Under the API Endpoints grab the URL and remove the Token section. Fill out the Authentication as pictured. For Query Auth, create a new Authentication for this scraper. Call it token and insert your token.
After choose send body, JSON and paste the code below.
{
"proxy": {
"useApifyProxy": true
},
"urls": [
"{{ $json.company_url }}"
]
}
Wait
The results will not be instant, so you’ll want a wait node. I chose 15 seconds.
HTTP Get Request
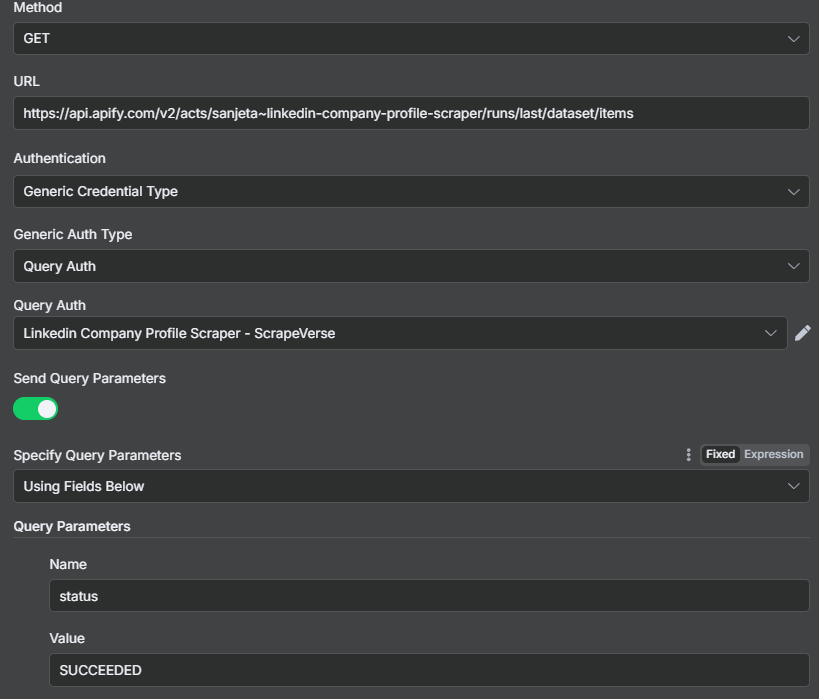
After waiting, our data should now be ready to go. We need another HTTP request.
Choose Get as the Method and grab the URL again from the API endpoints. We can use the same Query Auth as earlier.
Make sure the status is set to succeeded.
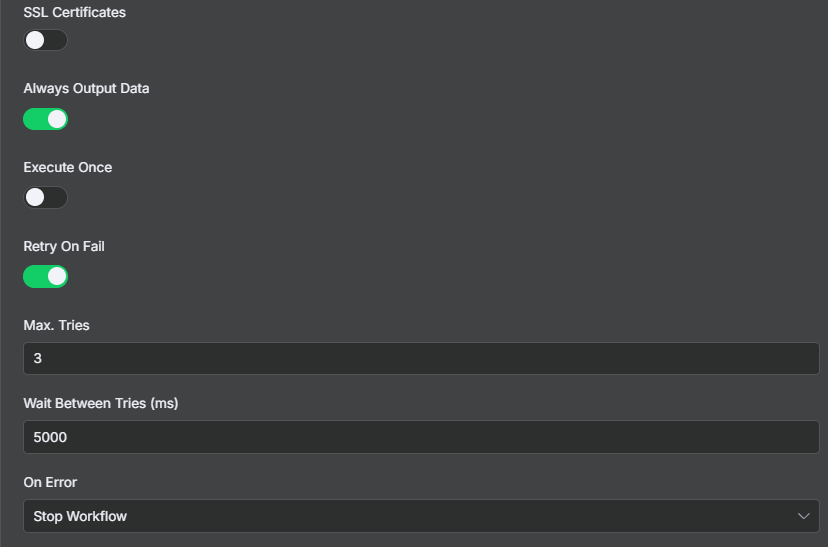
It wasn’t shown in the video but make sure you set these settings as well, just in case the data isn’t ready or if there are issues with it.
Google Sheets
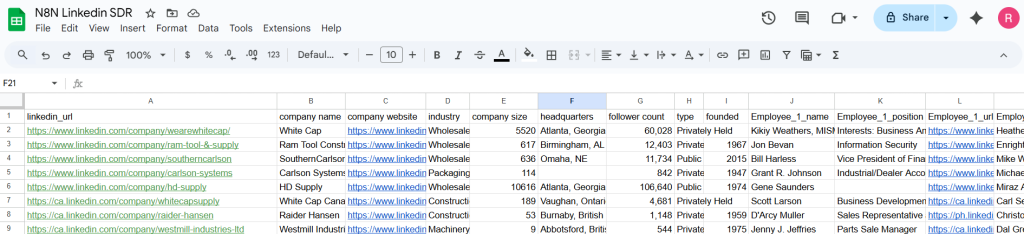
Now that we have our data, let’s look at adding it into Google Sheets. To make sure that we don’t have duplicates, select Append or Update Row. If there is a duplicate company, it will “Update” the row with new information ensuring we have unique results.
To do this though, we have to match on a column. Each company should have a unique url on LinkedIn, so we will use that.
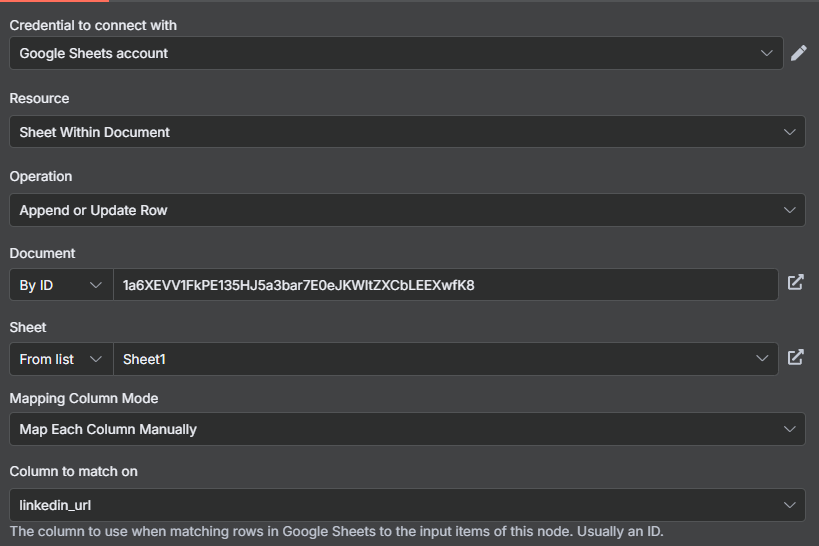
At the end, our results will look like this. But we are not done yet…
Python Code
Now we will want to randomize the similar company we choose to look at next. The reason we do this is that LinkedIn sometimes likes to pair companies 1:1 on their respective pages. For example the top spot on Lowe’s is Home Depot and the top spot on Home Depot is Lowe’s.
If we do not randomize this, we will get an infinite loop!
import json
import random
urls = []
similar_companies = _data.get("similar_companies", [])
# We want positions 1 through 3, i.e. indices 1, 2, 3
if len(similar_companies) > 1:
# Compute available slice
candidates = similar_companies[1:4] # up to index 3 included
if candidates:
random_company = random.choice(candidates)
link = random_company.get("link", "")
clean_link = link.split("?")[0]
urls.append(clean_link)
# Prepare result
return [
{
"company_url": urls
}
]
Merge
Since we ran the Sheets and Code in parallel, we should merge these together before moving on to the next loop.
If Condition
For every data merge, we have a runIndex counter in the background. By having a number here, we can filter how many times we want this program to run. Once the runIndex hits 20 (in this example) the program stops running. This is super important as without it, you will once again have an infinite loop.
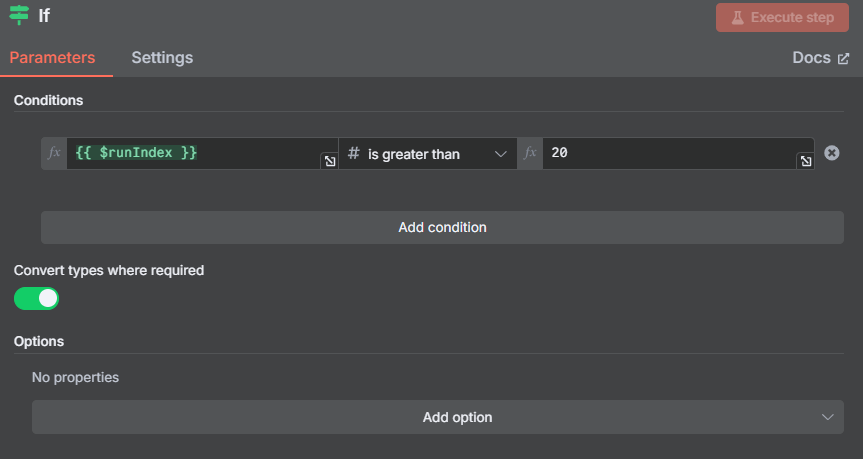
The Loop
If we have a runIndex of merge under 20, we go back in a loop. Start a new Post request and then go through the steps from above once again.
Final Thoughts
There are some other options to improve this workflow. I could have set the number of new entries in the sheet at the beginning to X rather then putting it in the If statement manually.
Additionally, it may have been interesting to upload a list of URLs in the first step and get 10-20 similar companies for each of them.
If this was helpful share it on LinkedIn and tag me. I’m also taking on Freelance Data and N8N customers!
