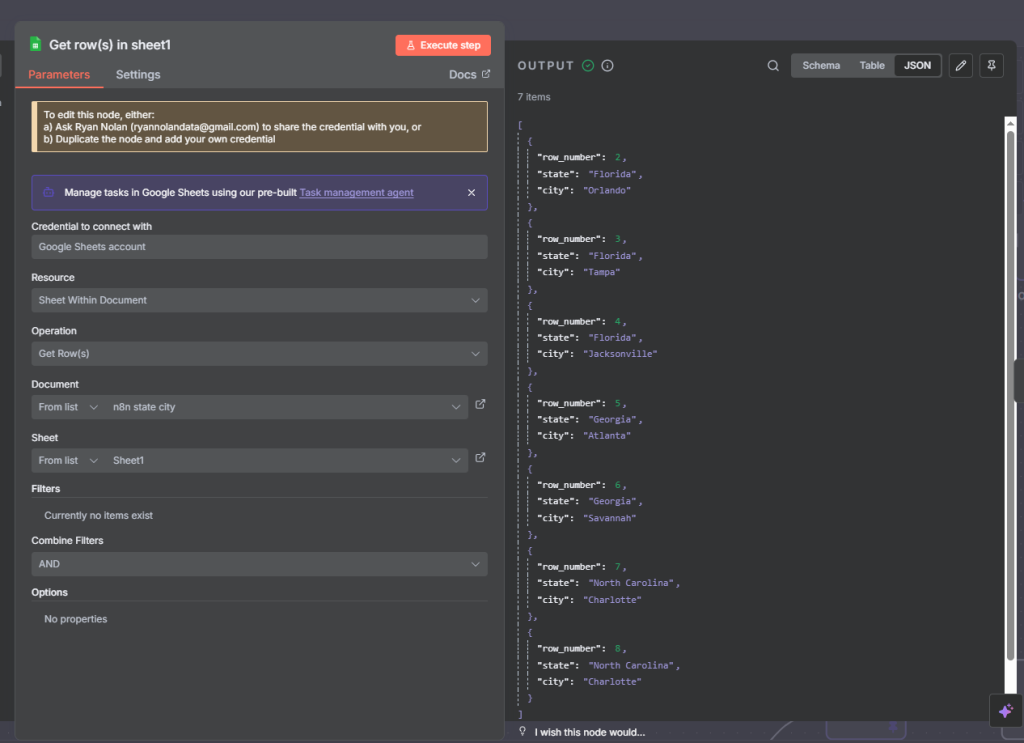
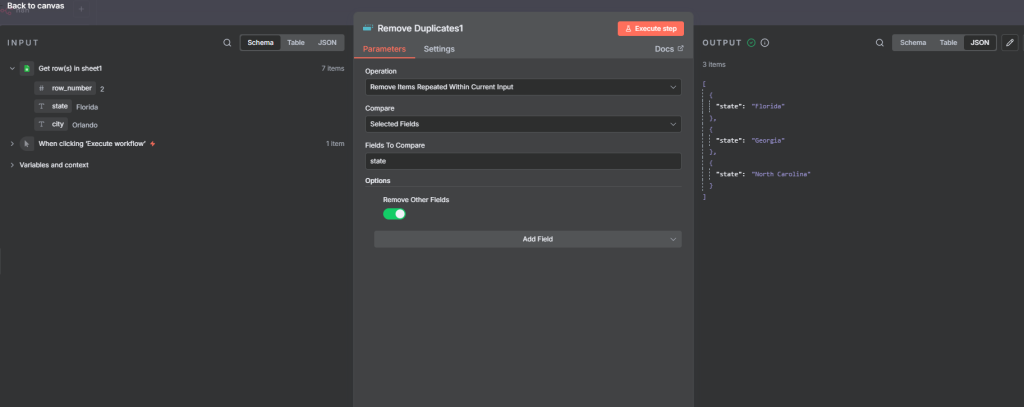
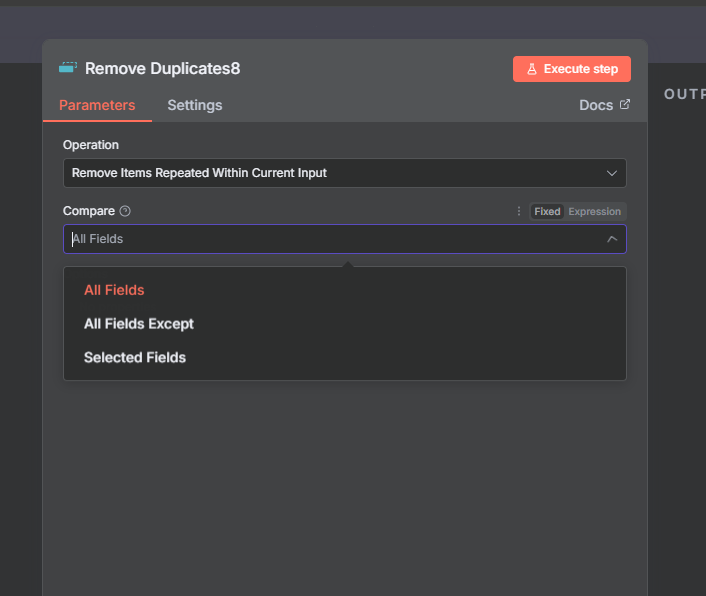
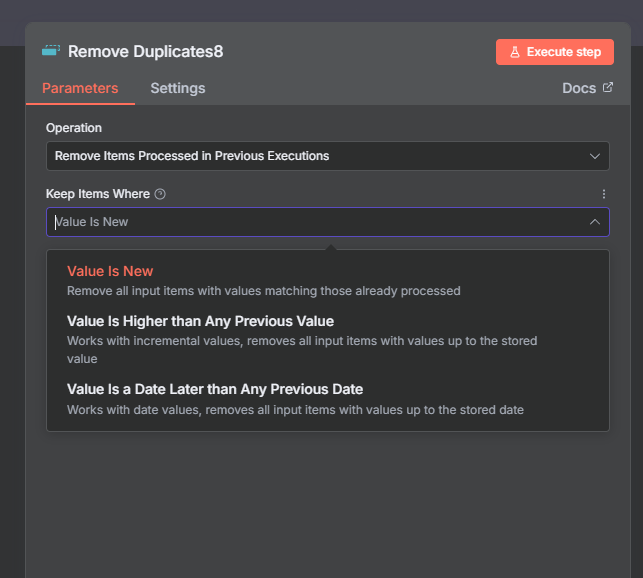
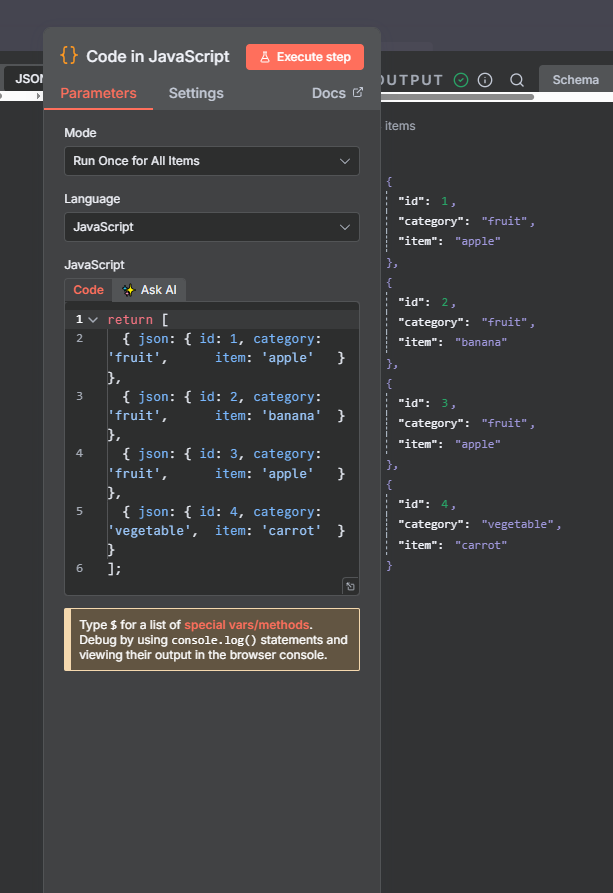
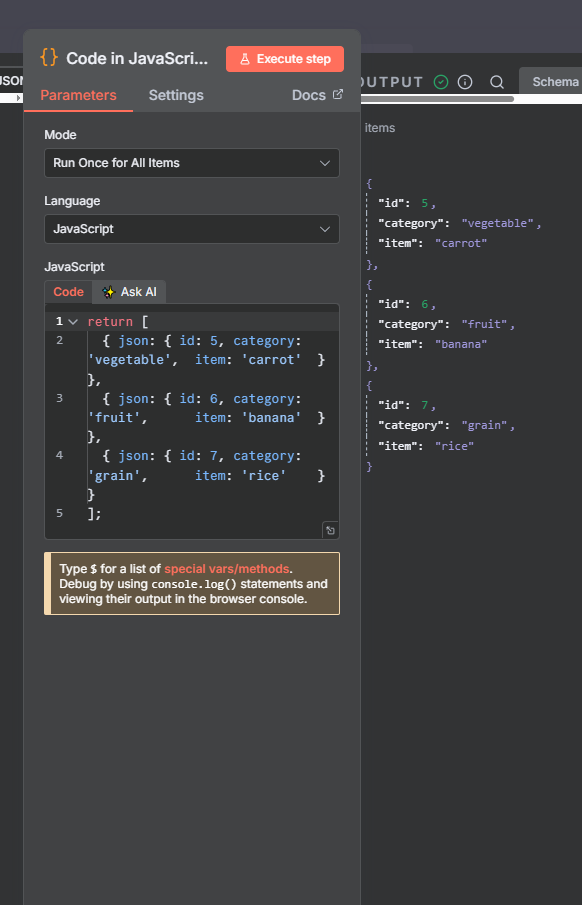
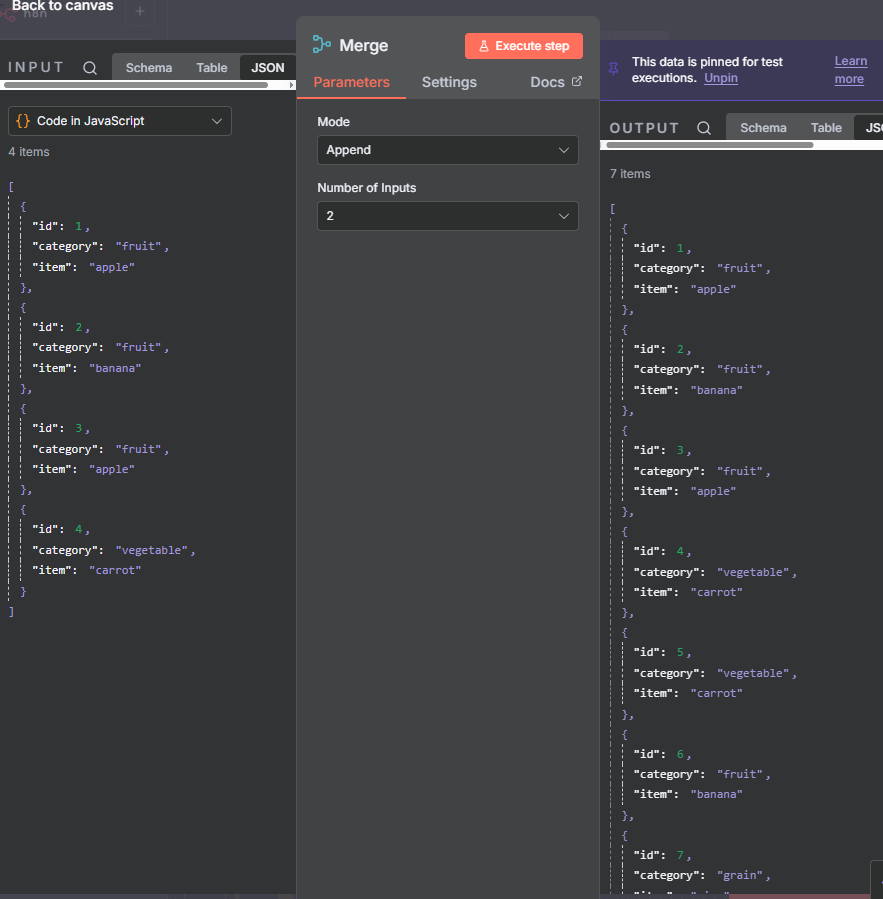
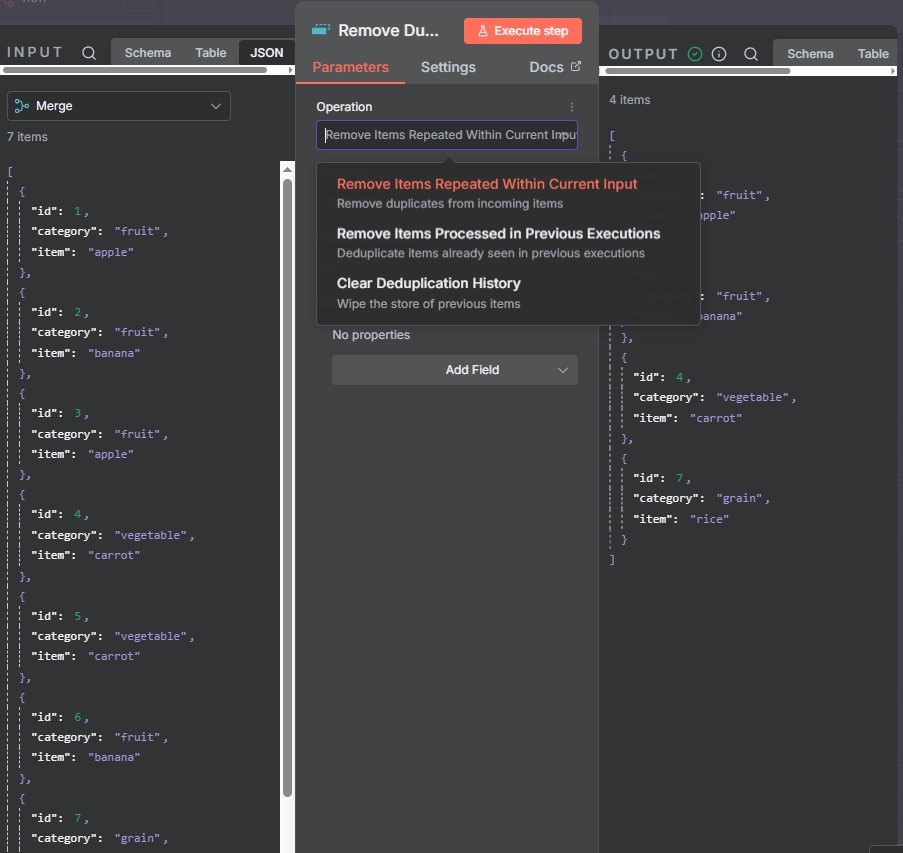
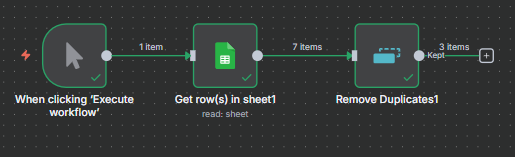
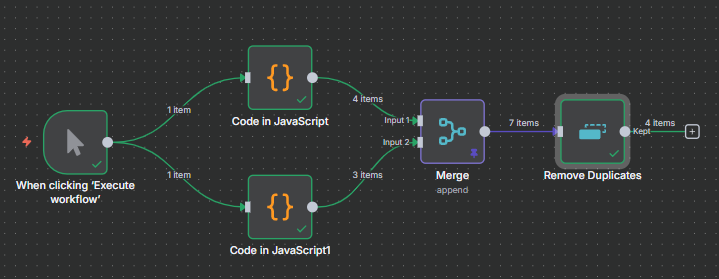
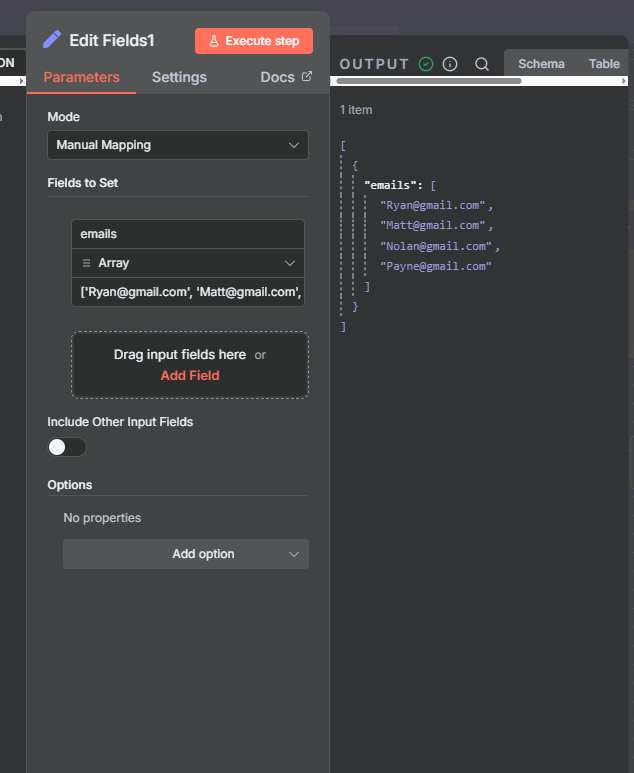
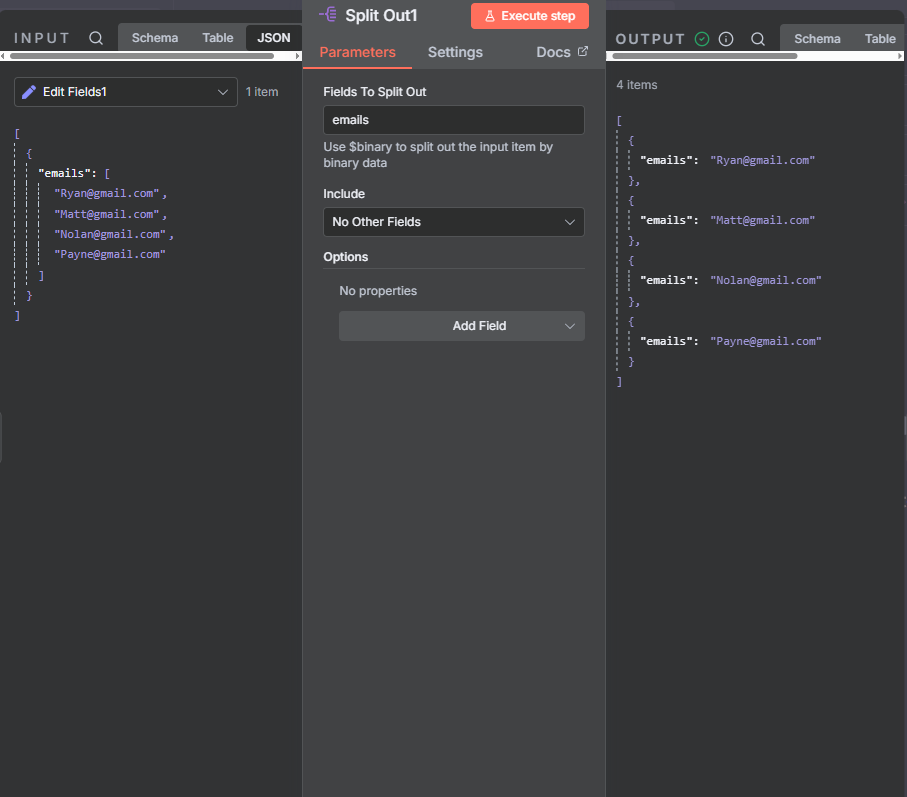
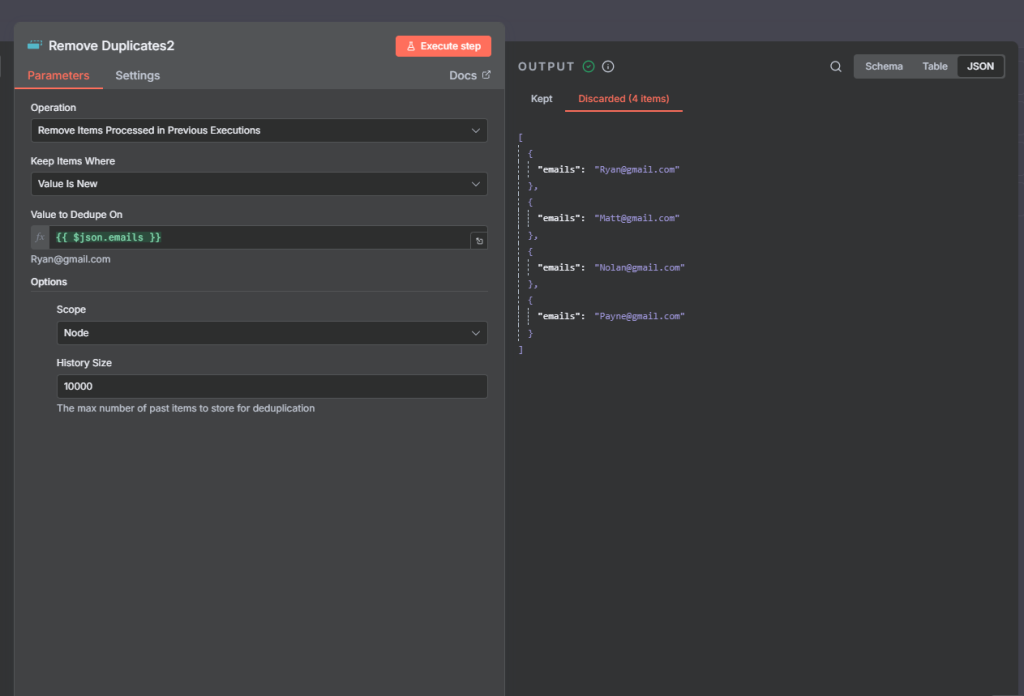
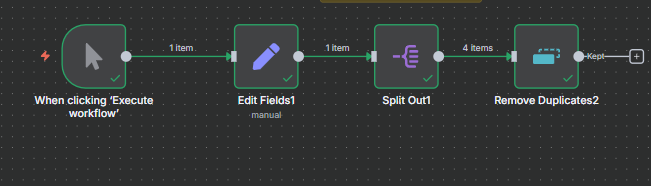

The n8n ClickUp integration (see n8n clickup node documentation) gives you 57 actions and 27 triggers to automate almost anything in your...
The n8n Notion integration lets you automate your Notion workspace without writing a single line of code. You can create pages, update...
Slack is one of the most popular integrations in any n8n workflow. Customers want daily data reports pushed into specific channels, onboarding...