import requests– Allows us to make HTTP requests to web pages.from bs4 import BeautifulSoup–It is used to parse and extract data from HTML content.import pandas as pd– It is used for organizing and manipulating data in table format.import re– It enables pattern matching using regular expressions.from time import sleep– It lets us pause the script for a set amount of time.import random– It is used to generate random values (e.g., for sleep delays).
import requests
from bs4 import BeautifulSoup
import pandas as pd
import re
from time import sleep
import random
Example 1 - Setting up a timer
Here , we create a timer that waits for 3 seconds between each rounds of the loop
for i in range(5):
print(f"Doing something... round {i+1}")
sleep(3) # wait 3 seconds
Example 2- setting up a random timer
Here we pick a random float between 1 and 5 seconds, then pause for the randomly chosen time.
for i in range(5):
print(f"Doing something... round {i+1}")
delay = random.uniform(1, 5) # float seconds between 1 and 5
print(f"Waiting {delay:.2f} seconds...")
sleep(delay)
Example 3 string format url
Here, we loop through page number 1 to 5,
We then create a url with the current oage number.
Then we display the url
for page in range(1, 6): # Pages 1 to 5
url = f"https://example.com/page={page}"
print(f"Fetching URL: {url}")
Example 4 Books to Scrape - static times
titles = [],prices = []– Create empty lists to store book titles and prices.page = 1– Start scraping from page 1.while page < 10:– Loop through pages 1 to 9.url = f"http://books.toscrape.com/catalogue/page-{page}.html"– Format the URL for each page.response = requests.get(url)– Fetch the page content.if response.status_code == 404: break– Stop if the page doesn’t exist.soup = BeautifulSoup(response.text, "html.parser")– Parse the HTML content.articles = soup.find_all("article", class_="product_pod")– Get all book items on the page.for article in articles:– Loop through each book item.title = article.h3.a["title"]– Extract the book title.price = article.find("p", class_="price_color").text.strip()– Extract and clean the book price.titles.append(title),prices.append(price)– Save the title and price.page += 1– Go to the next page.sleep(1)– Wait 1 second before the next request.
titles = []
prices = []
page = 1
while page < 10:
url = f"http://books.toscrape.com/catalogue/page-{page}.html"
response = requests.get(url)
if response.status_code == 404:
break
soup = BeautifulSoup(response.text, "html.parser")
articles = soup.find_all("article", class_="product_pod")
for article in articles:
title = article.h3.a["title"]
price = article.find("p", class_="price_color").text.strip()
titles.append(title)
prices.append(price)
page += 1
sleep(1) # polite delay
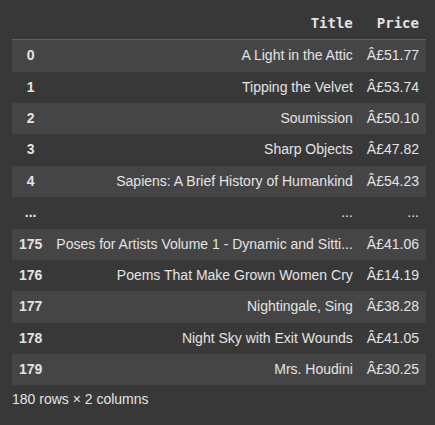
Here, we create a pandas DataFrame with column Title and Price populated with data gotten from our previous operation.
df = pd.DataFrame({
"Title": titles,
"Price": prices
})
Example 5 Hockey Website - Tables and multiple pages and a function and random timer
In this function, we define scrape_pages(num_pages) to scrape multiple pages from a website with a paginated table. We start by setting the base URL template and creating empty lists to store column headers and row data. For each page from 1 to the number specified, we format the URL and make a GET request to fetch the HTML content. We parse the response using BeautifulSoup and look for a table with the class "table". If a table isn’t found, we print a message and skip to the next page. On the first page, we extract the table headers. For every page, we loop through each table row with the class "team", extract and clean the cell text, and append it to our rows list. To avoid overwhelming the server, we pause for a random interval between 1 and 5 seconds after each request. Once all pages are processed, we use the collected headers and rows to create a Pandas DataFrame and return it.
def scrape_pages(num_pages):
base_url = "https://www.scrapethissite.com/pages/forms/?page={}"
headers = []
rows = []
for page in range(1, num_pages + 1):
url = base_url.format(page)
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
table = soup.find("table", {"class": "table"})
if not table:
print(f"No table found on page {page}")
continue
# Extract column headers on first page
if page == 1:
headers = [th.get_text(strip=True) for th in table.find_all("th")]
# Extract rows
for tr in table.find_all("tr", class_="team"):
cells = [td.get_text(strip=True) for td in tr.find_all("td")]
if cells:
rows.append(cells)
delay = random.uniform(1, 5)
sleep(delay) # polite delay to avoid overloading server
# Build DataFrame
df = pd.DataFrame(rows, columns=headers)
return df
df = scrape_pages(5)
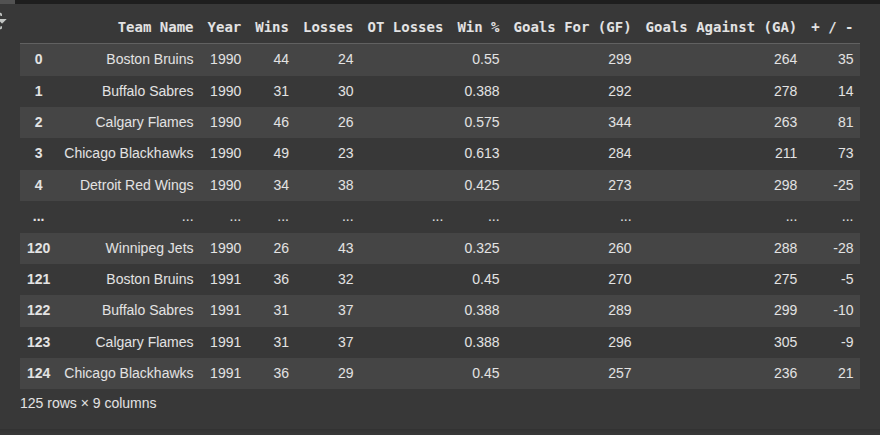
Lets filter based off data scraped.
Example - customer only wants to see winning teams
Here, we create a new dataframe ‘df2’ by filtering df to include only the rows where the number of Wins is greater than the number of Lossess.
This helps us keep only the teams with a winning record.
df2 = df[df['Wins'] > df['Losses']]
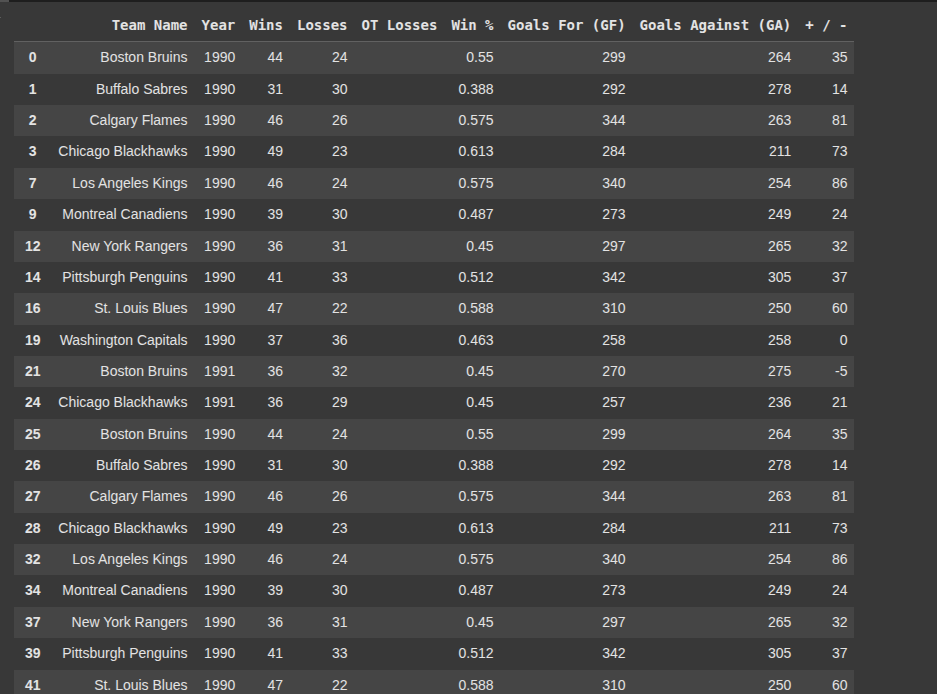
Finally we save dataframe.
df2.to_csv("scrapethissite_forms_stats.csv", index=False)
