import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.preprocessing import OrdinalEncoder, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.compose import make_column_transformer, ColumnTransformer
from sklearn.pipeline import Pipeline, make_pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from xgboost import XGBClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, GradientBoostingClassifier, ExtraTreesClassifier, VotingClassifier
from sklearn.model_selection import cross_val_score, StratifiedKFold, train_test_split, GridSearchCV
train_df = pd.read_csv('/kaggle/input/titanic/train.csv')
test_df = pd.read_csv('/kaggle/input/titanic/test.csv')
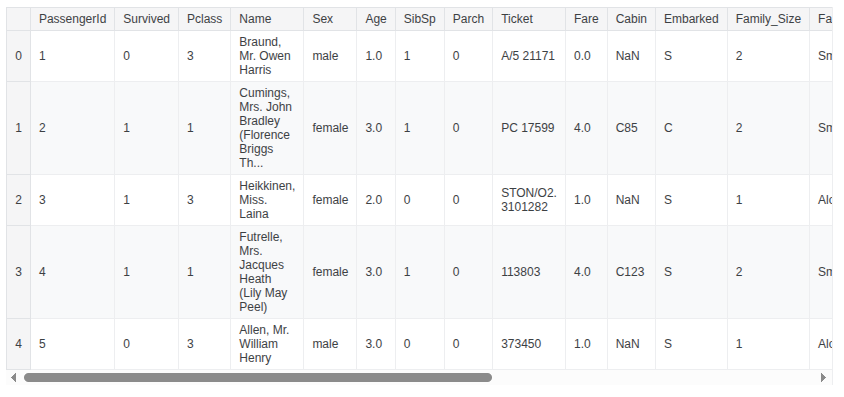
train_df.head()
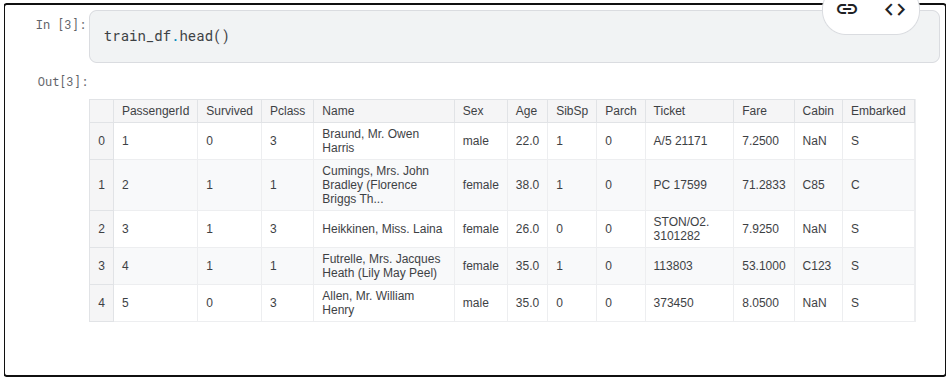
train_df.info()
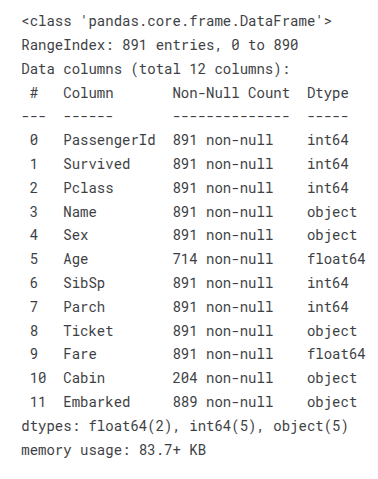
train_df.describe()
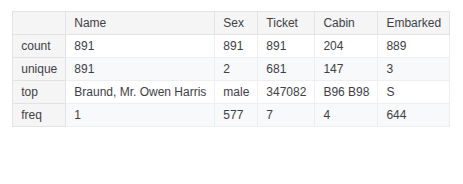
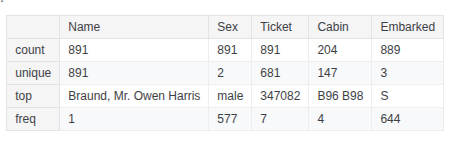
train_df.describe(include=['O'])
train_df.groupby(['Pclass'], as_index=False)['Survived'].mean()
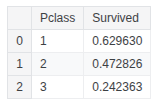
train_df.groupby(['Sex'], as_index=False)['Survived'].mean()
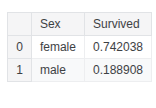
train_df.groupby(['SibSp'], as_index=False)['Survived'].mean()
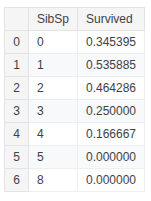
train_df.groupby(['Parch'], as_index=False)['Survived'].mean()
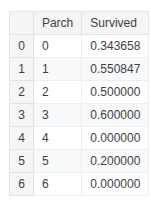
train_df['Family_Size'] = train_df['SibSp'] + train_df['Parch'] + 1
test_df['Family_Size'] = test_df['SibSp'] + test_df['Parch'] + 1
train_df.groupby(['Family_Size'], as_index=False)['Survived'].mean()
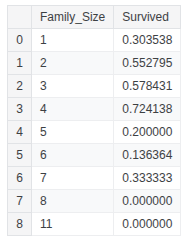
family_map = {1: 'Alone', 2: 'Small', 3: 'Small', 4: 'Small', 5: 'Medium', 6: 'Medium', 7: 'Large', 8: 'Large', 11: 'Large'}
train_df['Family_Size_Grouped'] = train_df['Family_Size'].map(family_map)
test_df['Family_Size_Grouped'] = train_df['Family_Size'].map(family_map)
train_df.groupby(['Family_Size_Grouped'], as_index=False)['Survived'].mean()
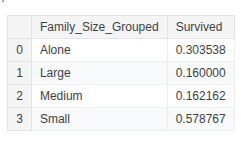
train_df.groupby(['Embarked'], as_index=False)['Survived'].mean()
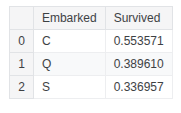
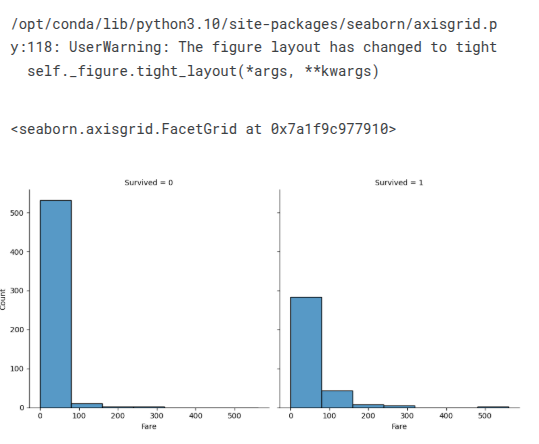
sns.displot(train_df, x='Age', col='Survived', binwidth=10, height=5)
train_df['Age_Cut'] = pd.qcut(train_df['Age'], 5)
test_df['Age_Cut'] = pd.qcut(test_df['Age'], 5)
train_df.groupby(['Age_Cut'], as_index=False)['Survived'].mean()
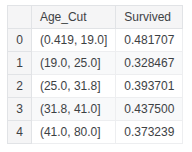
train_df.loc[train_df['Age'] <= 19, 'Age'] = 0
train_df.loc[(train_df['Age'] > 19) & (train_df['Age'] <= 25), 'Age'] = 1
train_df.loc[(train_df['Age'] > 25) & (train_df['Age'] <= 31.8), 'Age'] = 2
train_df.loc[(train_df['Age'] > 31.8) & (train_df['Age'] <= 41), 'Age'] = 3
train_df.loc[(train_df['Age'] > 41) & (train_df['Age'] <= 80), 'Age'] = 4
train_df.loc[train_df['Age'] > 80, 'Age']
test_df.loc[test_df['Age'] <= 19, 'Age'] = 0
test_df.loc[(test_df['Age'] > 19) & (test_df['Age'] <= 25), 'Age'] = 1
test_df.loc[(test_df['Age'] > 25) & (test_df['Age'] <= 31.8), 'Age'] = 2
test_df.loc[(test_df['Age'] > 31.8) & (test_df['Age'] <= 41), 'Age'] = 3
test_df.loc[(test_df['Age'] > 41) & (test_df['Age'] <= 80), 'Age'] = 4
test_df.loc[test_df['Age'] > 80, 'Age']
train_df.head()
sns.displot(train_df, x='Fare', col='Survived', binwidth=80, height=5)
train_df['Fare_Cut'] = pd.qcut(train_df['Fare'], 5)
test_df['Fare_Cut'] = pd.qcut(test_df['Fare'], 5)
train_df.groupby(['Fare_Cut'], as_index=False)['Survived'].mean()
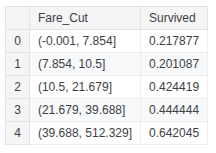
train_df.loc[train_df['Fare'] <= 7.854, 'Fare'] = 0
train_df.loc[(train_df['Fare'] > 7.854) & (train_df['Fare'] <= 10.5), 'Fare'] = 1
train_df.loc[(train_df['Fare'] > 10.5) & (train_df['Fare'] <= 21.679), 'Fare'] = 2
train_df.loc[(train_df['Fare'] > 21.679) & (train_df['Fare'] <= 39.688), 'Fare'] = 3
train_df.loc[(train_df['Fare'] > 39.688) & (train_df['Fare'] <= 512.329), 'Fare'] = 4
train_df.loc[train_df['Fare'] > 512.329, 'Fare']
test_df.loc[test_df['Fare'] <= 7.854, 'Fare'] = 0
test_df.loc[(test_df['Fare'] > 7.854) & (test_df['Fare'] <= 10.5), 'Fare'] = 1
test_df.loc[(test_df['Fare'] > 10.5) & (test_df['Fare'] <= 21.679), 'Fare'] = 2
test_df.loc[(test_df['Fare'] > 21.679) & (test_df['Fare'] <= 39.688), 'Fare'] = 3
test_df.loc[(test_df['Fare'] > 39.688) & (test_df['Fare'] <= 512.329), 'Fare'] = 4
test_df.loc[test_df['Fare'] > 512.329, 'Fare']

train_df['Name']

train_df['Title'] = train_df['Name'].str.split(pat= ",", expand=True)[1].str.split(pat= ".", expand=True)[0].apply(lambda x: x.strip())
test_df['Title'] = test_df['Name'].str.split(pat= ",", expand=True)[1].str.split(pat= ".", expand=True)[0].apply(lambda x: x.strip())
train_df.groupby(['Title'], as_index=False)['Survived'].mean()
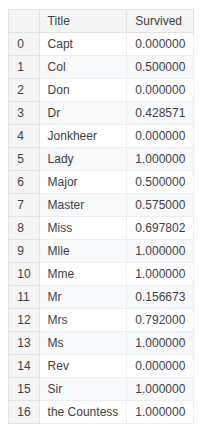
#military - Capt, Col, Major #noble - Jonkheer, the Countess, Don, Lady, Sir #unmaried Female - Mlle, Ms, Mme
train_df['Title'] = train_df['Title'].replace({
'Capt': 'Military',
'Col': 'Military',
'Major': 'Military',
'Jonkheer': 'Noble',
'the Countess': 'Noble',
'Don': 'Noble',
'Lady': 'Noble',
'Sir': 'Noble',
'Mlle': 'Noble',
'Ms': 'Noble',
'Mme': 'Noble'
})
test_df['Title'] = test_df['Title'].replace({
'Capt': 'Military',
'Col': 'Military',
'Major': 'Military',
'Jonkheer': 'Noble',
'the Countess': 'Noble',
'Don': 'Noble',
'Lady': 'Noble',
'Sir': 'Noble',
'Mlle': 'Noble',
'Ms': 'Noble',
'Mme': 'Noble'
})
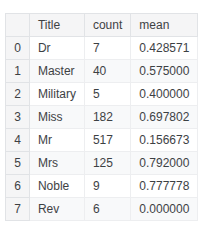
train_df.groupby(['Title'], as_index=False)['Survived'].agg(['count', 'mean'])
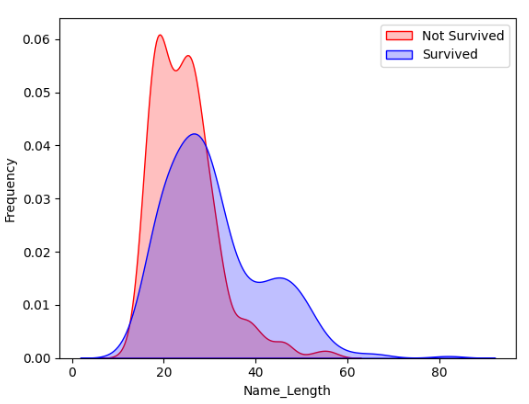
train_df['Name_Length'] = train_df['Name'].apply(lambda x: len(x))
test_df['Name_Length'] = test_df['Name'].apply(lambda x: len(x))
g = sns.kdeplot(train_df['Name_Length'][(train_df['Survived']==0) & (train_df['Name_Length'].notnull())], color='Red', fill=True)
g = sns.kdeplot(train_df['Name_Length'][(train_df['Survived']==1) & (train_df['Name_Length'].notnull())], ax=g, color='Blue', fill=True)
g.set_xlabel('Name_Length')
g.set_ylabel('Frequency')
g = g.legend(['Not Survived', 'Survived'])
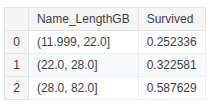
train_df['Name_LengthGB'] = pd.qcut(train_df['Name_Length'], 3)
test_df['Name_LengthGB'] = pd.qcut(test_df['Name_Length'], 3)
train_df.groupby(['Name_LengthGB'], as_index=False)['Survived'].mean()
train_df.loc[train_df['Name_Length'] <= 22, 'Name_Size'] = 0
train_df.loc[(train_df['Name_Length'] > 22) & (train_df['Name_Length'] <= 28), 'Name_Size'] = 1
train_df.loc[(train_df['Name_Length'] > 28) & (train_df['Name_Length'] <= 82), 'Name_Size'] = 2
train_df.loc[train_df['Name_Length'] > 82, 'Name_Size']
test_df.loc[test_df['Name_Length'] <= 22, 'Name_Size'] = 0
test_df.loc[(test_df['Name_Length'] > 22) & (test_df['Name_Length'] <= 28), 'Name_Size'] = 1
test_df.loc[(test_df['Name_Length'] > 28) & (test_df['Name_Length'] <= 82), 'Name_Size'] = 2
test_df.loc[test_df['Name_Length'] > 82, 'Name_Size']
train_df.head()
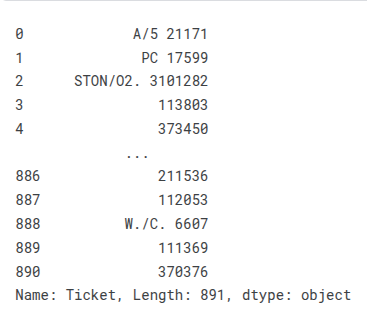
train_df['Ticket']
train_df['TicketNumber'] = train_df['Ticket'].apply(lambda x: pd.Series({'Ticket': x.split()[-1]}))
test_df['TicketNumber'] = test_df['Ticket'].apply(lambda x: pd.Series({'Ticket': x.split()[-1]}))
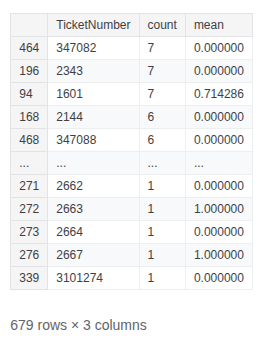
train_df.groupby(['TicketNumber'], as_index=False)['Survived'].agg(['count', 'mean']).sort_values('count', ascending=False)
train_df.groupby('TicketNumber')['TicketNumber'].transform('count')

train_df['TicketNumberCounts'] = train_df.groupby('TicketNumber')['TicketNumber'].transform('count')
test_df['TicketNumberCounts'] = test_df.groupby('TicketNumber')['TicketNumber'].transform('count')
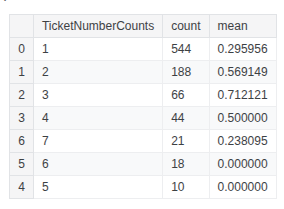
train_df.groupby(['TicketNumberCounts'], as_index=False)['Survived'].agg(['count', 'mean']).sort_values('count', ascending=False)
train_df['Ticket']
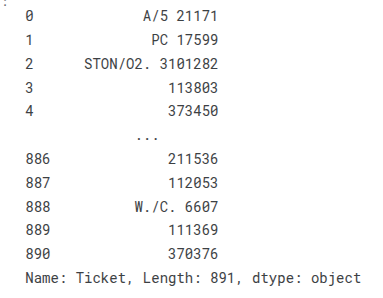
train_df['Ticket'].str.split(pat=" ", expand=True)
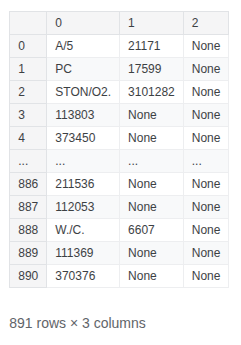
train_df['TicketLocation'] = np.where(train_df['Ticket'].str.split(pat=" ", expand=True)[1].notna(), train_df['Ticket'].str.split(pat=" ", expand=True)[0].apply(lambda x: x.strip()), 'Blank')
test_df['TicketLocation'] = np.where(test_df['Ticket'].str.split(pat=" ", expand=True)[1].notna(), test_df['Ticket'].str.split(pat=" ", expand=True)[0].apply(lambda x: x.strip()), 'Blank')
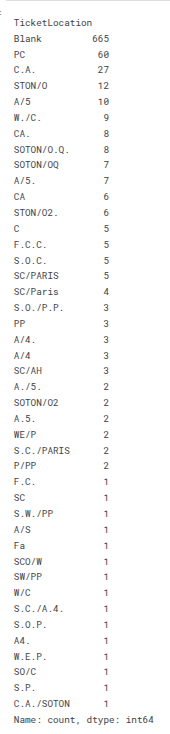
train_df['TicketLocation'].value_counts()
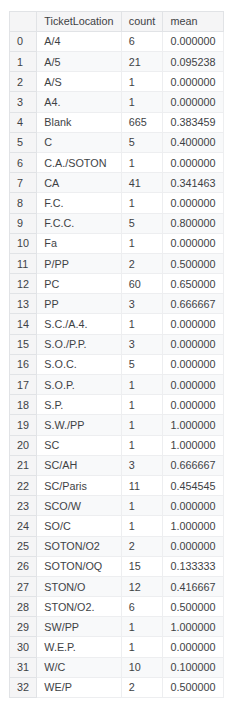
train_df['TicketLocation'] = train_df['TicketLocation'].replace({
'SOTON/O.Q.':'SOTON/OQ',
'C.A.':'CA',
'CA.':'CA',
'SC/PARIS':'SC/Paris',
'S.C./PARIS':'SC/Paris',
'A/4.':'A/4',
'A/5.':'A/5',
'A.5.':'A/5',
'A./5.':'A/5',
'W./C.':'W/C',
})
test_df['TicketLocation'] = test_df['TicketLocation'].replace({
'SOTON/O.Q.':'SOTON/OQ',
'C.A.':'CA',
'CA.':'CA',
'SC/PARIS':'SC/Paris',
'S.C./PARIS':'SC/Paris',
'A/4.':'A/4',
'A/5.':'A/5',
'A.5.':'A/5',
'A./5.':'A/5',
'W./C.':'W/C',
})
train_df.groupby(['TicketLocation'], as_index=False)['Survived'].agg(['count', 'mean'])
train_df['Cabin'] = train_df['Cabin'].fillna('U')
train_df['Cabin'] = pd.Series([i[0] if not pd.isnull(i) else 'x' for i in train_df['Cabin']])
test_df['Cabin'] = test_df['Cabin'].fillna('U')
test_df['Cabin'] = pd.Series([i[0] if not pd.isnull(i) else 'x' for i in test_df['Cabin']])
train_df.groupby(['Cabin'], as_index=False)['Survived'].agg(['count', 'mean'])
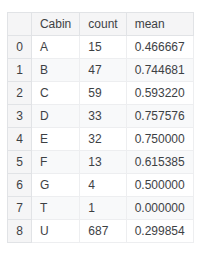
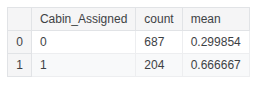
train_df['Cabin_Assigned'] = train_df['Cabin'].apply(lambda x: 0 if x in ['U'] else 1)
test_df['Cabin_Assigned'] = test_df['Cabin'].apply(lambda x: 0 if x in ['U'] else 1)
train_df.groupby(['Cabin_Assigned'], as_index=False)['Survived'].agg(['count', 'mean'])
train_df.head()
train_df.shape

test_df.shape

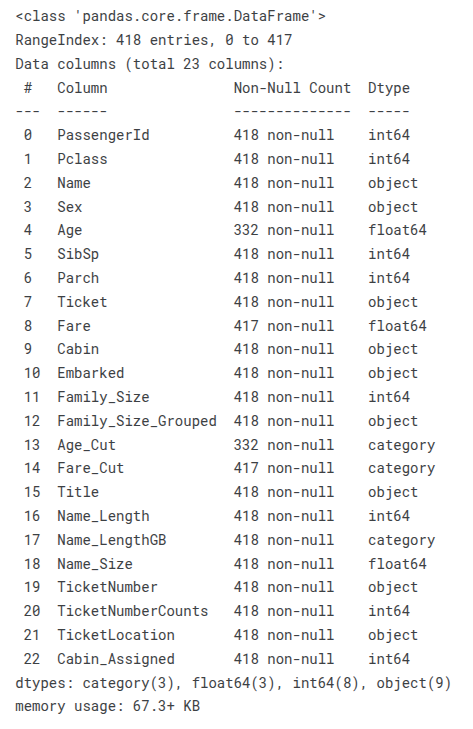
train_df.info()
train_df.columns

test_df.info()
train_df['Age'].fillna(train_df['Age'].mean(), inplace=True)
test_df['Age'].fillna(test_df['Age'].mean(), inplace=True)
test_df['Fare'].fillna(test_df['Fare'].mean(), inplace=True)
ohe = OneHotEncoder(sparse_output=False)
ode = OrdinalEncoder
SI = SimpleImputer(strategy='most_frequent')
ode_cols = ['Family_Size_Grouped']
ohe_cols = ['Sex', 'Embarked']
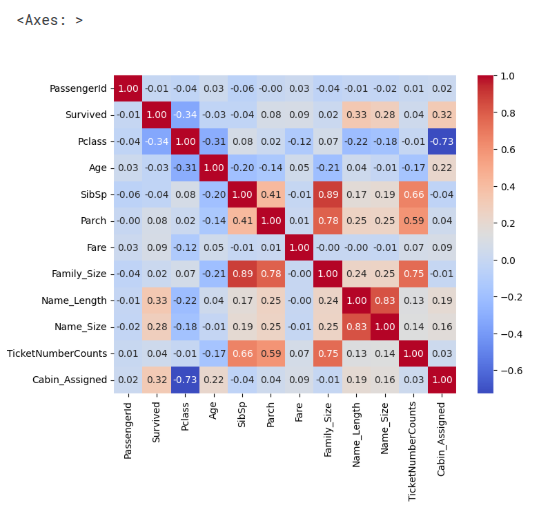
correlation_matrix = train_df.corr(numeric_only=True)
# Create a heatmap using Seaborn
plt.figure(figsize=(8, 6)) # Adjust the figure size as needed
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt=".2f")
#NEW Drop Sibsp, Parch, TicketNumberCounts
#new
X = train_df.drop(['Survived', 'SibSp', 'Parch'], axis=1)
y = train_df['Survived']
X_test = test_df.drop(['Age_Cut', 'Fare_Cut', 'SibSp', 'Parch'], axis=1)
#OLD #X = train_df.drop(['Survived'], axis=1) #y = train_df['Survived'] #X_test = test_df.drop(['Age_Cut', 'Fare_Cut'], axis=1)
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, stratify = y, random_state=21)
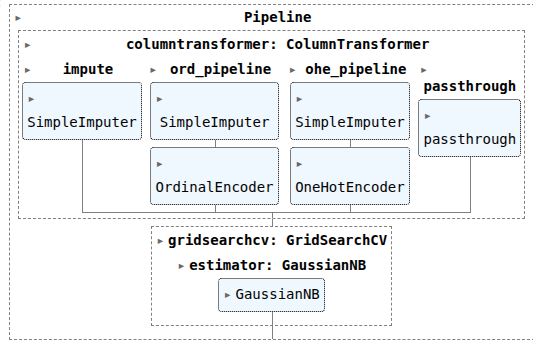
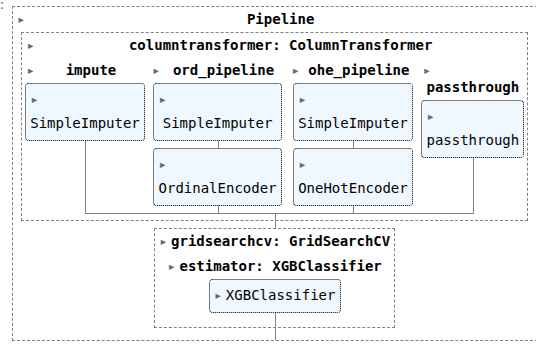
ordinal_pipeline = Pipeline(steps=[
('impute', SimpleImputer(strategy='most_frequent')),
('ord', OrdinalEncoder(handle_unknown='use_encoded_value', unknown_value=-1))
])
ohe_pipeline = Pipeline(steps=[
('impute', SimpleImputer(strategy='most_frequent')),
('one-hot', OneHotEncoder(handle_unknown = 'ignore', sparse_output=False))
])
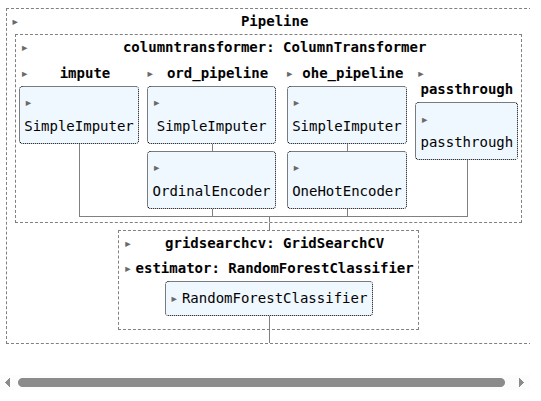
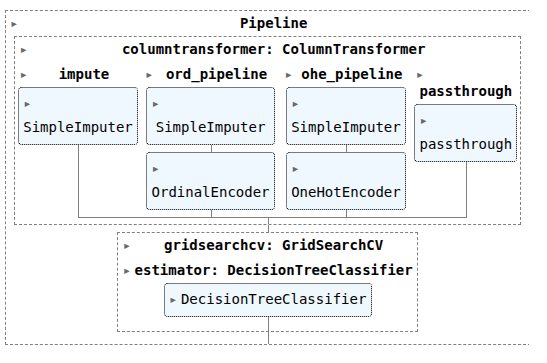
col_trans = ColumnTransformer(transformers=[
('impute', SI, ['Age']),
('ord_pipeline', ordinal_pipeline, ode_cols),
('ohe_pipeline', ohe_pipeline, ohe_cols),
# ('passthrough', 'passthrough', ['Pclass', 'TicketNumberCounts', 'Cabin_Assigned', 'Name_Size', 'Age', 'Fare'])
('passthrough', 'passthrough', ['Pclass', 'Cabin_Assigned', 'Name_Size', 'Age', 'Fare', 'TicketNumberCounts'])
],
remainder='drop',
n_jobs=-1)
rfc = RandomForestClassifier()
param_grid = {
'n_estimators': [150, 200, 300, 500],
'min_samples_split': [5, 10, 15],
'max_depth': [10, 13, 15, 17, 20],
'min_samples_leaf': [2, 4, 5, 6],
'criterion': ['gini', 'entropy'],
}
CV_rfc = GridSearchCV(estimator=rfc, param_grid=param_grid, cv=StratifiedKFold(n_splits=5))
pipefinalrfc = make_pipeline(col_trans, CV_rfc)
pipefinalrfc.fit(X_train, y_train)
print(CV_rfc.best_params_)
print(CV_rfc.best_score_)

dtc = DecisionTreeClassifier()
param_grid = {
'min_samples_split': [5, 10, 15],
'max_depth': [10, 20, 30],
'min_samples_leaf': [1, 2, 4],
'criterion': ['gini', 'entropy'],
}
CV_dtc = GridSearchCV(estimator=dtc, param_grid=param_grid, cv=StratifiedKFold(n_splits=5))
pipefinaldtc = make_pipeline(col_trans, CV_dtc)
pipefinaldtc.fit(X_train, y_train)
print(CV_dtc.best_params_)
print(CV_dtc.best_score_)

knn = KNeighborsClassifier()
param_grid = {
'n_neighbors': [3, 5, 7, 9, 11],
'weights': ['uniform', 'distance'],
'algorithm': ['auto', 'ball_tree', 'kd_tree', 'brute'],
'p': [1,2],
}
CV_knn = GridSearchCV(estimator=knn, param_grid=param_grid, cv=StratifiedKFold(n_splits=5))
pipefinalknn = make_pipeline(col_trans, CV_knn)
pipefinalknn.fit(X_train, y_train)
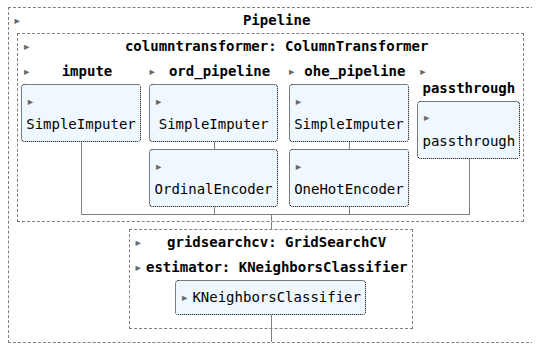
print(CV_knn.best_params_)
print(CV_knn.best_score_)

svc = SVC(probability=True)
param_grid = {
'C': [100,10, 1.0, 0.1, 0.001, 0.001],
'kernel':['linear', 'poly', 'rbf', 'sigmoid'],
}
CV_svc = GridSearchCV(estimator=svc, param_grid=param_grid, cv=StratifiedKFold(n_splits=5))
pipefinalsvc = make_pipeline(col_trans, CV_svc)
pipefinalsvc.fit(X_train, y_train)
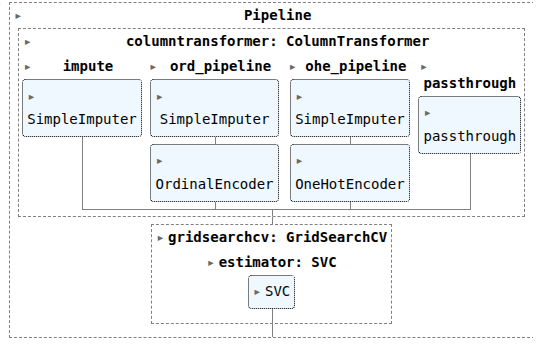
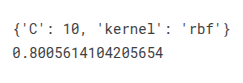
print(CV_svc.best_params_)
print(CV_svc.best_score_)
lr = LogisticRegression()
param_grid = {
'C': [100,10, 1.0, 0.1, 0.001, 0.001],
}
CV_lr = GridSearchCV(estimator=lr, param_grid=param_grid, cv=StratifiedKFold(n_splits=5))
pipefinallr= make_pipeline(col_trans, CV_lr)
pipefinallr.fit(X_train, y_train)
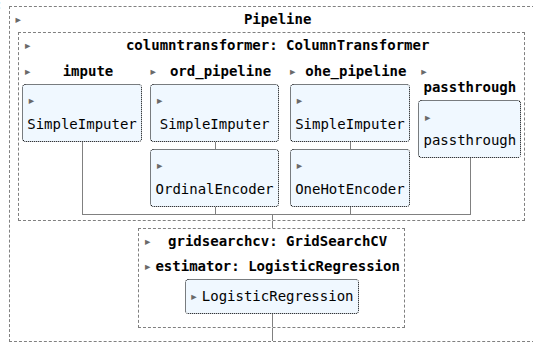
print(CV_lr.best_params_)
print(CV_lr.best_score_)
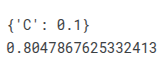
gnb = GaussianNB()
param_grid = {
'var_smoothing': [0.00000001, 0.000000001, 0.00000001],
}
CV_gnb = GridSearchCV(estimator=gnb, param_grid=param_grid, cv=StratifiedKFold(n_splits=5))
pipefinalgnb= make_pipeline(col_trans, CV_gnb)
pipefinalgnb.fit(X_train, y_train)
print(CV_gnb.best_params_)
print(CV_gnb.best_score_)
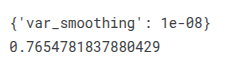
xg = XGBClassifier()
param_grid = {
'booster': ['gbtree', 'gblinear','dart'],
}
CV_xg = GridSearchCV(estimator=xg, param_grid=param_grid, cv=StratifiedKFold(n_splits=5))
pipefinalxg= make_pipeline(col_trans, CV_xg)
pipefinalxg.fit(X_train, y_train)
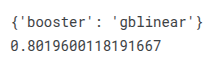
print(CV_xg.best_params_)
print(CV_xg.best_score_)
abc = AdaBoostClassifier()
dtc_2 = DecisionTreeClassifier(criterion = 'entropy', max_depth=10,min_samples_leaf=4, min_samples_split=10)
svc_2 = SVC(probability=True, C=10, kernel='rbf')
lr_2 = LogisticRegression(C=0.1)
lr_3 = LogisticRegression(C=0.2)
lr_4 = LogisticRegression(C=0.05)
param_grid = {
'estimator': [dtc_2, svc_2, lr_2],
'n_estimators': [5, 10, 25, 50, 100],
'algorithm': ['SAMME', 'SAMME.R'],
'learning_rate': [(0.97 + x / 100) for x in range(1, 7)]
}
CV_abc = GridSearchCV(estimator=abc, param_grid=param_grid, cv=StratifiedKFold(n_splits=5))
pipefinalabc= make_pipeline(col_trans, CV_abc)
pipefinalabc.fit(X_train, y_train)
print(CV_abc.best_params_)
print(CV_abc.best_score_)

etc = ExtraTreesClassifier()
param_grid = {
"max_features": [1, 3, 10],
"min_samples_split": [2, 3, 10],
"min_samples_leaf": [1, 3, 10],
"n_estimators" :[100,300],
}
CV_etc = GridSearchCV(estimator=etc, param_grid=param_grid, cv=StratifiedKFold(n_splits=5))
pipefinaletc= make_pipeline(col_trans, CV_etc)
pipefinaletc.fit(X_train, y_train)
print(CV_etc.best_params_)
print(CV_etc.best_score_)

GBC = GradientBoostingClassifier()
param_grid = {
'n_estimators' : [300, 400, 500],
'learning_rate': [ 0.1, 0.3, 0.6, 1.0],
'max_depth': [8, 10, 12],
'min_samples_leaf': [50, 100, 120, 150],
'max_features': [0.1, 0.3, 0.5]
}
CV_gbc = GridSearchCV(estimator=GBC, param_grid=param_grid, cv=StratifiedKFold(n_splits=5))
pipefinalgbc= make_pipeline(col_trans, CV_gbc)
pipefinalgbc.fit(X_train, y_train)
print(CV_gbc.best_params_)
print(CV_gbc.best_score_)

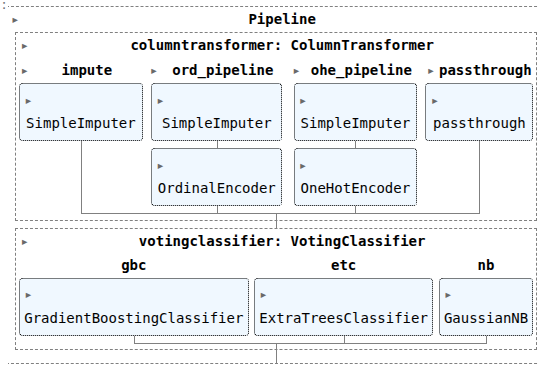
vc1 = VotingClassifier([('gbc', CV_gbc.best_estimator_),
('etc', CV_etc.best_estimator_),
('nb', CV_gnb.best_estimator_)
], voting='hard', weights=[1,2,3] )
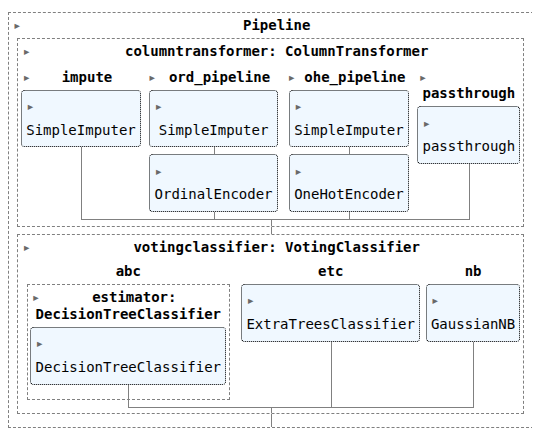
vc2 = VotingClassifier([('abc', CV_abc.best_estimator_),
('etc', CV_etc.best_estimator_),
('nb', CV_gnb.best_estimator_)
], voting='hard', weights=[1,2,3] )
#1,2,3 is the best performing one
pipefinalcv1 = make_pipeline(col_trans, vc1)
pipefinalcv2 = make_pipeline(col_trans, vc2)
pipefinalcv1.fit(X_train, y_train)
pipefinalcv2.fit(X_train, y_train)
Y_pred = pipefinalrfc.predict(X_test)
Y_pred2 = pipefinaldtc.predict(X_test)
Y_pred3 = pipefinalknn.predict(X_test)
Y_pred4 = pipefinalsvc.predict(X_test)
Y_pred5 = pipefinallr.predict(X_test)
Y_pred6 = pipefinalgnb.predict(X_test)
Y_pred7 = pipefinalxg.predict(X_test)
Y_pred8 = pipefinalabc.predict(X_test)
Y_pred9 = pipefinaletc.predict(X_test)
Y_pred10 = pipefinalgbc.predict(X_test)
Y_pred11 = pipefinalcv1.predict(X_test)
Y_pred12 = pipefinalcv2.predict(X_test)
submission = pd.DataFrame({
'PassengerId': test_df['PassengerId'],
'Survived': Y_pred
})
submission2 = pd.DataFrame({
'PassengerId': test_df['PassengerId'],
'Survived': Y_pred2
})
submission3 = pd.DataFrame({
'PassengerId': test_df['PassengerId'],
'Survived': Y_pred3
})
submission4 = pd.DataFrame({
'PassengerId': test_df['PassengerId'],
'Survived': Y_pred4
})
submission5 = pd.DataFrame({
'PassengerId': test_df['PassengerId'],
'Survived': Y_pred5
})
submission6 = pd.DataFrame({
'PassengerId': test_df['PassengerId'],
'Survived': Y_pred6
})
submission7 = pd.DataFrame({
'PassengerId': test_df['PassengerId'],
'Survived': Y_pred7
})
submission8 = pd.DataFrame({
'PassengerId': test_df['PassengerId'],
'Survived': Y_pred8
})
submission9 = pd.DataFrame({
'PassengerId': test_df['PassengerId'],
'Survived': Y_pred9
})
submission10 = pd.DataFrame({
'PassengerId': test_df['PassengerId'],
'Survived': Y_pred10
})
submission11 = pd.DataFrame({
"PassengerId": test_df["PassengerId"],
"Survived": Y_pred11
})
submission12 = pd.DataFrame({
"PassengerId": test_df["PassengerId"],
"Survived": Y_pred12
})
submission.to_csv('/kaggle/working/submission929_1.csv', index=False)
submission2.to_csv('/kaggle/working/submission929_2.csv', index=False)
submission3.to_csv('/kaggle/working/submission929_3.csv', index=False)
submission4.to_csv('/kaggle/working/submission929_4.csv', index=False)
submission5.to_csv('/kaggle/working/submission929_5.csv', index=False)
submission6.to_csv('/kaggle/working/submission929_6.csv', index=False)
submission7.to_csv('/kaggle/working/submission929_7.csv', index=False)
submission8.to_csv('/kaggle/working/submission101_8.csv', index=False)
submission9.to_csv('/kaggle/working/submission101_9.csv', index=False)
submission10.to_csv('/kaggle/working/submission101_10.csv', index=False)
submission11.to_csv('/kaggle/working/submission101_11.csv', index=False)
submission12.to_csv('/kaggle/working/submission101_12.csv', index=False)
