Voting Classifier
Boosting Accuracy with Voting Classifiers
In machine learning, combining multiple models often leads to better performance than relying on a single one. A Voting Classifier is a simple ensemble method that does just that — it aggregates predictions from several models to improve accuracy.
There are two types:
Hard Voting: Takes the majority vote from all classifiers (the most common prediction).
Soft Voting: Averages predicted probabilities and picks the class with the highest average. This requires models that support predict_proba().
Even if individual models are imperfect, their combined output can reduce errors and generalize better. You can tune a Voting Classifier by:
Choosing between "hard" and "soft" voting.
Assigning weights to give more influence to stronger models.
Voting Classifiers are a practical way to build more reliable systems by leveraging the strengths of multiple models.
we import pandas as pd
we also import make_classification from sklearn.datasets to generate synthetic data.
n_samples=2000: Generates 2000 rows.
n_features=10: Each sample has 10 features.
n_informative=8: 8 features are actually useful for prediction.
n_redundant=2: 2 features are linear combinations of the informative ones.
train_test_split: Splits data into 80% training and 20% testing.
import pandas as pd
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=2000, n_features=10, n_informative=8, n_redundant=2, random_state=11)
Next we imort train_test_split from sklearn so we can split our X, y data into training and test sets.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=11)
Next we import cross_val_score to evaluate the models performance using cross-validation.
from sklearn.model_selection import cross_val_score
We also import Gaussian Naive Bayes, which is a fast and simple probabilistic classifier that works well on many problems, especially when features are independent and normally distributed.
from sklearn.naive_bayes import GaussianNB
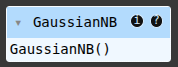
gnb = GaussianNB()
gnb.fit(X_train, y_train)
cross_val_score(gnb, X_train, y_train, cv=3).mean()
from sklearn.linear_model import LogisticRegression
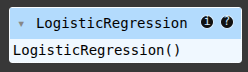
lr = LogisticRegression()
lr.fit(X_train, y_train)
cross_val_score(lr, X_train, y_train, cv=3).mean()
from sklearn.ensemble import RandomForestClassifier
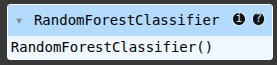
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
cross_val_score(rfc, X_train, y_train, cv=3).mean()
from sklearn.ensemble import VotingClassifier
vc = VotingClassifier([('NaiveBayes', gnb), ('LogisticRegression', lr), ('RandomForestClassifier', rfc)])
cross_val_score(vc, X_train, y_train, cv=3).mean()
param_grid = {'voting':['hard', 'soft'],
'weights':[(1,1,1), (2,1,1), (1,2,1), (1,1,2)]}
from sklearn.model_selection import GridSearchCV
vc2 = GridSearchCV(vc, param_grid, cv=5, n_jobs=-1)
vc2.fit(X_train, y_train)
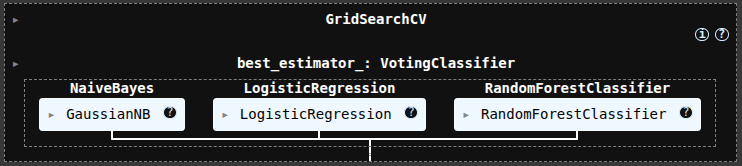
vc2.best_params_
vc2.best_score_
vc3 = VotingClassifier([('NaiveBayes', gnb), ('LogisticRegression', lr), ('RandomForestClassifier', rfc)], voting='soft', weights=[1,1,2])
vc3.fit(X_train, y_train)

cross_val_score(vc3, X_train, y_train, cv=3).mean()
Ryan is a Data Scientist at a fintech company, where he focuses on fraud prevention in underwriting and risk. Before that, he worked as a Data Analyst at a tax software company. He holds a degree in Electrical Engineering from UCF.