
Adaptive Boosting, or AdaBoost, is a boosting algorithm that combines multiple low-accuracy (weak) models to form a single high-accuracy (strong) model. It...
train_df = train_df.drop(columns=['PoolQC', 'MiscFeature', 'Alley', 'Fence', 'GarageYrBlt', 'GarageCond', 'BsmtFinType2']) test_df = test_df.drop(columns=['PoolQC', 'MiscFeature', 'Alley', 'Fence', 'GarageYrBlt', 'GarageCond', 'BsmtFinType2']) #drop GarageArea or GarageCars...
https://www.kaggle.com/code/ryannolan1/titanic-voting-classifier-0-78947?scriptVersionId=149342442&cellId=2https://www.kaggle.com/code/ryannolan1/titanic-voting-classifier-0-78947?scriptVersionId=149342442&cellId=2 #military - Capt, Col, Major #noble - Jonkheer, the Countess, Don, Lady, Sir #unmaried Female - Mlle, Ms, Mme #NEW Drop...
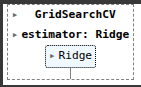
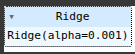
We would be looking at tuning hyperparameters with Scikit-Learn. Scikit-Learn is a powerful machine learning library for Python. It provides simple ,...
PCA (Principal Component Analysis) in Python using Scikit-learn is a technique used to reduce the number of features in a dataset while...