Python Pandas JSON
JSON (JavaScript Object Notation) is a lightweight, human-readable data interchange format that is widely used for both data storage and transfer. It is structured using key-value pairs and supports various data types, including strings, numbers, booleans, arrays, and nested objects. JSON is a standard format commonly used in APIs and web data, which makes it highly interoperable and easy to integrate with programming tools such as Python and libraries like pandas.
import pandas as pd
import json
import requests
from pandas import json_normalize
Example 1 Create DataFrame From Json String
# Sample JSON data as a string
data_json = '''
[
{
"athlete": "Jim Walmsley",
"year": 2019,
"time": "14:09:28"
},
{
"athlete": "Courtney Dauwalter",
"year": 2023,
"time": "15:29:34"
},
{
"athlete": "Killian Jornet",
"year": 2022,
"time": null
}
]
'''
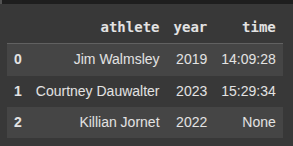
Here, we parse JSON string and load them into a DataFrame.
data = json.loads(data_json)
df = pd.DataFrame(data)
Example 2 Dataframe to Json Output
Here we convert the DataFrame df into a JSON file.
The output file name is “western_states_results.json”
orient=”records”: Each row of the DataFrame will be written as a separate JSON object in a list (i.e., an array of records).
df.to_json("western_states_results.json", orient="records", indent=2)
Example 3 Read in Json File to Dataframe
Here, we read a JSON file and convert it into a DataFrame.
df = pd.read_json('western_states_results.json')
Example 4 different orient options
Here we create a pandas DataFrame named df with two columns “name” and “laps”
df = pd.DataFrame({
"name": ["Killian", "Bob"],
"laps": [48, 40]
})
orient="records" generates a list of dictionaries, with each dictionary representing a row in the DataFrame. This format is commonly used in APIs and JSON Lines due to its simplicity and ease of parsing.
json_str = df.to_json(orient="records")
print(json_str)
orient="index" creates a dictionary where the keys are the DataFrame’s index values and the values are dictionaries representing each row.
json_str = df.to_json(orient="split")
print(json_str)
orient="columns"generates a JSON object where the keys are the column names, and the values are dictionaries that map each index to its corresponding value in that column.
json_str = df.to_json(orient="columns")
print(json_str)
Example 5 Explode with Json
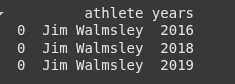
The variable data is a Python list containing one dictionary. This dictionary represents an athlete and the years they competed.
data = [
{
"athlete": "Jim Walmsley",
"years": [2016, 2018, 2019]
}
]
Next, we convert the data into a dataFrame.
df = pd.DataFrame(data)
This takes the df DataFrame with the columns ‘years’ containing lists and “explodes” that column so that each element in the list becomes a separate row.
df_exploded = df.explode('years')
print(df_exploded)
Example 6 from an API
api_key = ' '
base_url = 'http://api.marketstack.com/v1/eod'
Here the params dictionary holds the API key, the stock symbol(AAPL), and the number of data points to fetch (5).
# Parameters
params = {
'access_key': api_key,
'symbols': 'AAPL', # Example: Apple Inc.
'limit': 5 # Number of data points to retrieve
}
Next we make the api request.
response = requests.get(base_url, params=params)
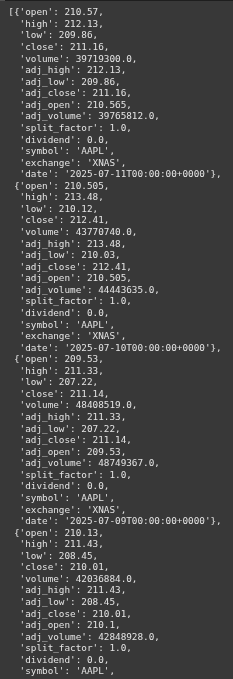
Then we extract ‘data’ field from the JSON response.
eod_data = data.get('data', [])
eod_data
Next we create a pandasDataFrame using the eod data.
df = pd.DataFrame(eod_data)

Example 7 Nested Json - Normalize and Flatten
Normalization here means transforming nested JSON into a flat DataFrame, where each row is a single record and nested structures are expanded into separate columns or rows.
data = {
"player": "Babe Ruth",
"cards": [
{
"year": 1914,
"card_set": "Baltimore News",
"details": {
"grade": "VG 3",
"estimated_value_usd": 6000000,
"rarity": "extremely rare"
}
},
{
"year": 1933,
"card_set": "Goudey",
"variations": [
{
"number": 53,
"color": "yellow background",
"grade": "NM-MT 8",
"estimated_value_usd": 500000
},
{
"number": 144,
"color": "full body pose",
"grade": "EX 5",
"estimated_value_usd": 150000
}
]
}
]
}
Here, we turn the list of card objects into a flat table, including shared metadata like year and card_set.
# Normalize top-level cards
df_cards = pd.json_normalize(
data['cards'],
sep='_',
record_prefix='',
meta=['year', 'card_set'],
record_path=None
)
Here, we load and flatten the cards list from the json.
Then we check if a details column (containing nested dictionares) exists, we expand that into individual columns.
# Flatten 'details' if it exists
df_details = pd.json_normalize(data['cards'], record_path=None, meta=['year', 'card_set'])
if 'details' in df_details.columns:
df_details = pd.concat([df_details.drop(columns='details'), df_details['details'].apply(pd.Series)], axis=1)
Here, we flatten the ‘variations’ data only for cards that have it.
We filter the list of cards to include only those that contain a ‘variations’ key.
# Flatten 'variations' only where they exist
cards_with_variations = [c for c in data['cards'] if 'variations' in c]
df_variations = pd.json_normalize(
cards_with_variations,
record_path='variations',
meta=['year', 'card_set'],
errors='ignore'
)
df_details

df_variations

Ryan is a Data Scientist at a fintech company, where he focuses on fraud prevention in underwriting and risk. Before that, he worked as a Data Analyst at a tax software company. He holds a degree in Electrical Engineering from UCF.
[…] JSON is used quite a bit when working with APIs or AI, so let’s look at how we can create a Dataframe with it in Pandas. […]