When working with large or fragmented datasets in Python, combining multiple dataframes into a cohesive whole is a common task for data scientists. One of the most powerful and flexible tools available in the Pandas library for this purpose is pd.concat().
By utilizing Pandas’ concat() function, data scientists can efficiently stack dataframes either vertically (by rows) or horizontally (by columns), depending on the structure and analysis goals of their data
This tutorial will go over both approaches. If you want to watch a visual representation of the code provided, a YouTube video is linked down below.
Tutorial Set Up
Before we jump into using concat, we have to import in Pandas and create two dataframes.
import pandas as pd
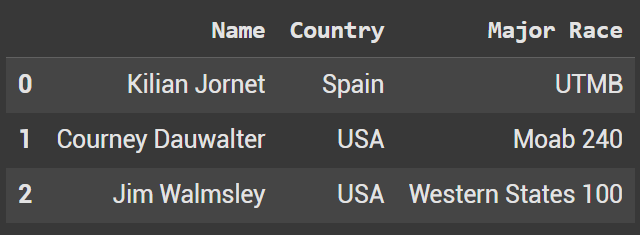
Our first dataframe will be created from a dictionary filled with ultra runners. We have the Name, Country, and Major Race for each runner.
ultra_runners = {
'Name': ['Kilian Jornet', 'Courney Dauwalter', 'Jim Walmsley'],
'Country': ['Spain', 'USA', 'USA'],
'Major Race': ['UTMB', 'Moab 240', 'Western States 100']
}
Pass the dictionary into pd.DataFrame() and we now have a dataframe.
ultra_runners_df = pd.DataFrame(ultra_runners)
ultra_runners_df.head()
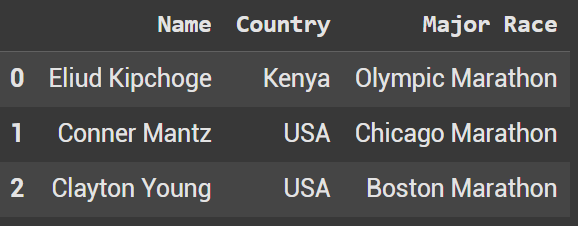
Our second dictionary is full of Marathon runners. We still have the same format as above: Name, Country, and Major Race.
marathon_runners = {
'Name': ['Eliud Kipchoge', 'Conner Mantz', 'Clayton Young'],
'Country': ['Kenya', 'USA', 'USA'],
'Major Race': ['Olympic Marathon', 'Chicago Marathon', 'Boston Marathon']
}
marathon_runners_df = pd.DataFrame(marathon_runners)
marathon_runners_df.head()
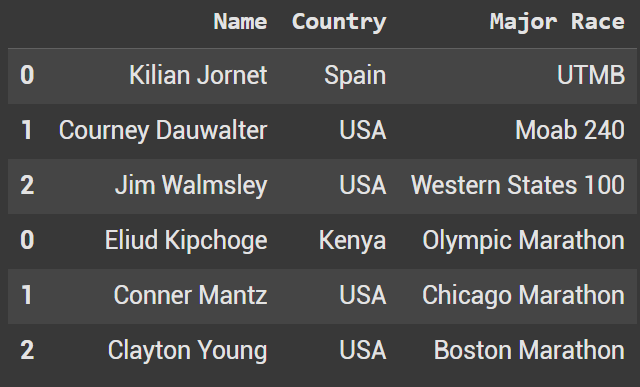
Example 1 - Concat Roiws
In our first example we want to stack the two dataframes by rows.
To accomplish this we use pd.concat and then populate each dataframe into a list. The first dataframe will be the one you want on top.
df_run_combined = pd.concat([ultra_runners_df, marathon_runners_df])
df_run_combined.head(10)
As you can see we were able to stack the two dataframes. One thing to call out though, the original indexes for each dataframe were brought over. We need to fix this.
There are two approaches we can take, so let’s look at the first which is resetting the index.
Example 2 - Reset Index
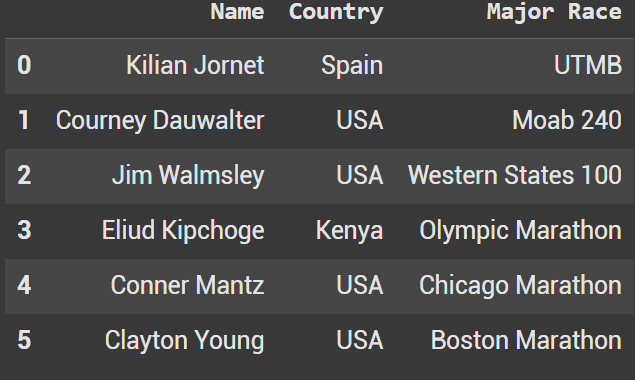
Resetting the index is quite simple. We use.reset_index(drop=True) and it should be fixed. As you’ll see below the index is now 0 through 5.
df_combined_reset = df_run_combined.reset_index(drop=True)
df_combined_reset.head(10)
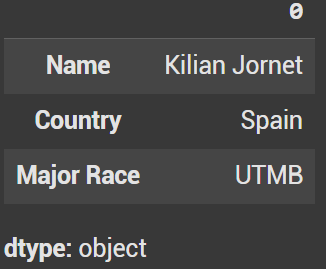
Now that the index is fixed, we can use iloc. In this example, we use iloc[3] to get Eliud Kiphchoge.
df_combined_reset.iloc[3]

If we use iloc[0] we can get Kilian Jornet.
df_combined_reset.iloc[0]
Example 3 - Concat Keys
Let’s look at another approach. For this one, we will use keys which allows you to define each dataframe.
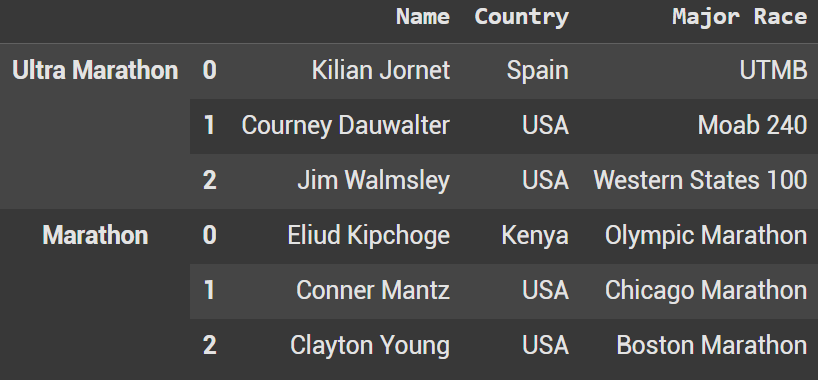
Like with the earlier concat, we will use a list. This time, pass in strings that you want to use to identify each dataframe. In this example we use Ultra Marathon and Marathon.
df_combined_keys = pd.concat([ultra_runners_df, marathon_runners_df], keys=['Ultra Marathon', 'Marathon'])
df_combined_keys.head(10)
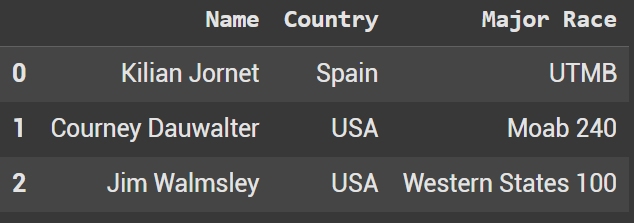
Now that we have keys, we can use .loc to grab the original dataframes. In this line below we can grab the original Ultra Marathon dataframe.
df_combined_keys.loc['Ultra Marathon']
This line of code grabe Marathon.
df_combined_keys.loc['Marathon']
Example 4 - Concat Columns
In the previous examples, we looked at how you can concat rows. Now let’s move to columns. This isn’t used as often as when you typically want to utilize merge when building out a new column, but regardless let’s go over how to do it.
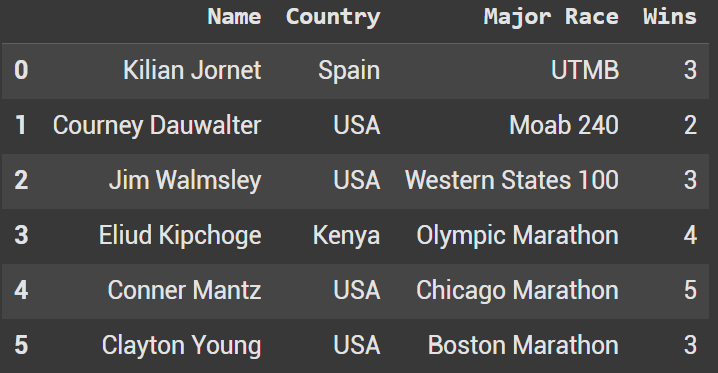
We first want to create a new dataframe called running_wins_df. This only has the wins for each runner. If this dataframe has the runner name attatched to it, we would be better off using a left or inner merge. However, since this data is missing we will use concat and assume that the index matches up for each runner.
running_wins = {
'Wins': [3, 2, 3, 4, 5, 3]
}
running_wins_df = pd.DataFrame(running_wins)
running_wins_df.head(10)

This code will look nearly identical to the examples above. The only difference is that we have a new parameter that defines the axis. By default axis=0 which concats rows. Since we are adding in a column, we have to use axis=1.
Additionally, it’s worth calling out that in this example we are combining the dataframe that we reset the index on.
df_combined_columns = pd.concat([df_combined_reset, running_wins_df], axis=1)
df_combined_columns.head(10)