Retrieval-Augmented Generation (RAG) systems have become one of the most effective architectures for building intelligent, context-aware AI applications. Whether you’re developing a chatbot that answers questions based on documentation or an AI assistant that searches through proprietary files, one of the most critical components in your RAG pipeline is vector embeddings.
This article will explain what vector embeddings are, why they’re important, and how to use OpenAI’s small and large embedding models and Pinecone as the vector database to make them work well.
Before we start, if you are looking for help with a n8n project, we are taking on customers. Head over to our n8n Automation Engineer page.
What Are Vector Embeddings?
At their core, vector embeddings are numbers that describe data, usually text, images, or audio, and let computers figure out how semantically similar two things are.
When we use RAG, embeddings let us turn our text data into number vectors that hold meaning instead of just words.
Think of the RAG pipeline:
You start with a large document (e.g., a PDF, article, or report).
You split it into smaller chunks using text splitters.
Each chunk is then converted into a vector using an embedding model.
These vectors are stored in a vector database (like Pinecone).
Later, when a user submits a query, that query is also embedded into a vector. The system then compares this query vector against all the stored document vectors to find the most semantically similar chunks.
Why Similarity Matters
Embeddings help AI understand that some pieces of text are related even if they don’t share the same words.
For instance:
The phrases “Billy Strings” and “Eddie Vedder” both refer to musicians, so their embeddings will be close together in vector space.
Similarly, “1888 Old Judge cards” and “1889 N43 Allen and Ginter cards” will also be close—since they’re both baseball card sets.
In contrast, a term like “100K Ultra Marathon” will have an embedding far away from those, since it’s unrelated.
In short:
Related items = close embeddings.
Unrelated items = distant embeddings.
The Importance of Using the Same Embedding Model
A crucial rule when working with embeddings is to always use the sawe embedding model for both your stored data and your queries.
For example:
If you embed your documents using
text-embedding-3-large, then your query must also be embedded usingtext-embedding-3-large.Mixing models (e.g., embedding with “small” and querying with “large”) will lead to inconsistent results or outright errors, since the numerical representations differ in size and meaning.
Embedding Model Dimensions
The dimension of an embedding refers to the number of numerical values in the vector.
For OpenAI’s latest models:
text-embedding-3-large → 3,072 dimensions
text-embedding-3-small → 1,536 dimensions
Higher dimensions capture richer, more nuanced semantic relationships, leading to better accuracy, but at higher cost and compute requirements.
In general:
Use large embeddings for accuracy-critical systems.
Use small embeddings for lightweight or cost-sensitive applications.
Setting Up OpenAI Embeddings with Pinecone
Let’s walk through how to set up embeddings and store them in a Pinecone vector database.
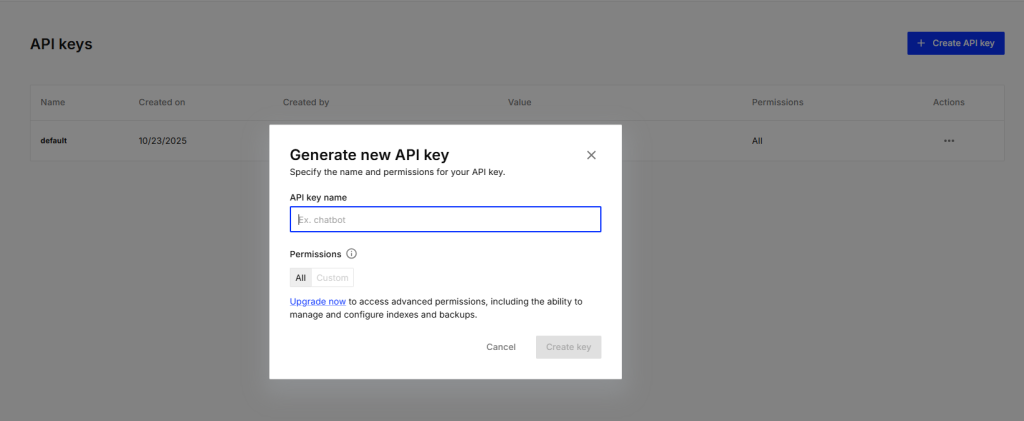
1. Get Your Pinecone API Key
Log into Pinecone.
Navigate to API Keys → create a new one.
Copy the key—you’ll use it for authentication in your workflow.
2. Prepare Your Data
You’ll typically upload a document (for example, a PDF) through a form submission.
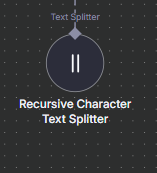
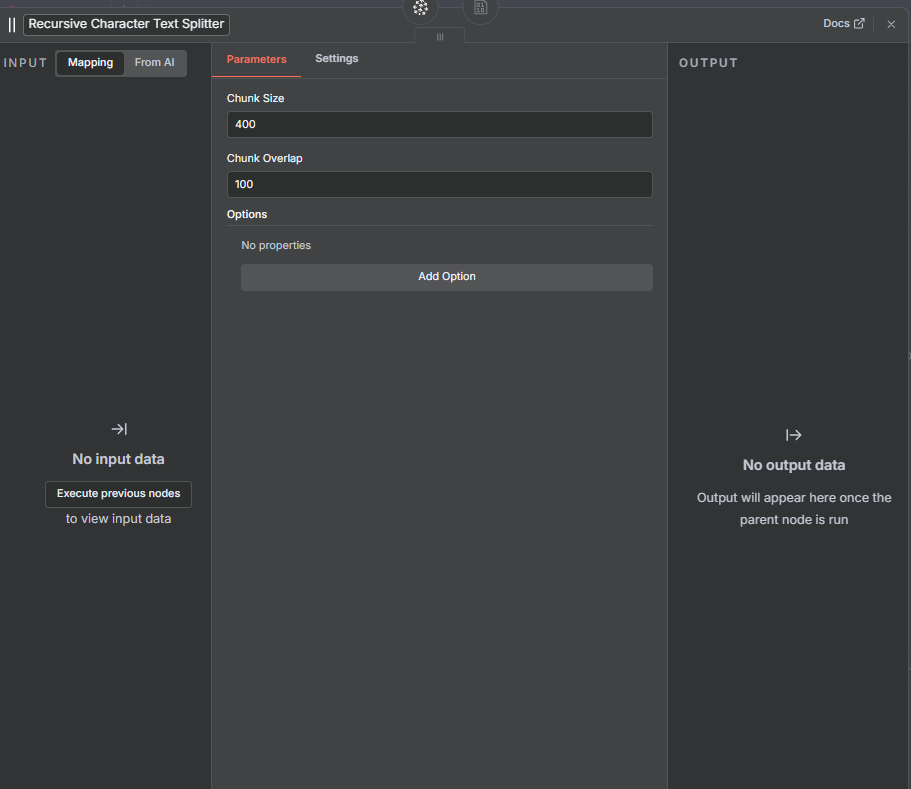
Before embedding, use a text splitter (e.g., recursive text splitter) to chunk your document:
Chunk size: 400 characters
Overlap: 100 characters
This ensures each piece of text is manageable and contextually coherent.
Create a Pinecone Index
In Pinecone:
Click Create Index.
Name it (e.g.,
rush-largeorrush-small).Choose the embedding configuration:
For large →
text-embedding-3-large(dimensions = 3072)For small →
text-embedding-3-small(dimensions = 1536)
Region: AWS (e.g.,
us-east-1or Virginia default)Click Create Index.
⚠️ Be sure your dimension count matches the embedding model exactly, or you’ll get errors when uploading vectors.
Embed and Store the Data
In your workflow (e.g., using AnyN, LangChain, or a custom pipeline):
Use OpenAI Embeddings to convert each text chunk into a vector.
Store each vector in your Pinecone index with metadata (e.g., title, source).

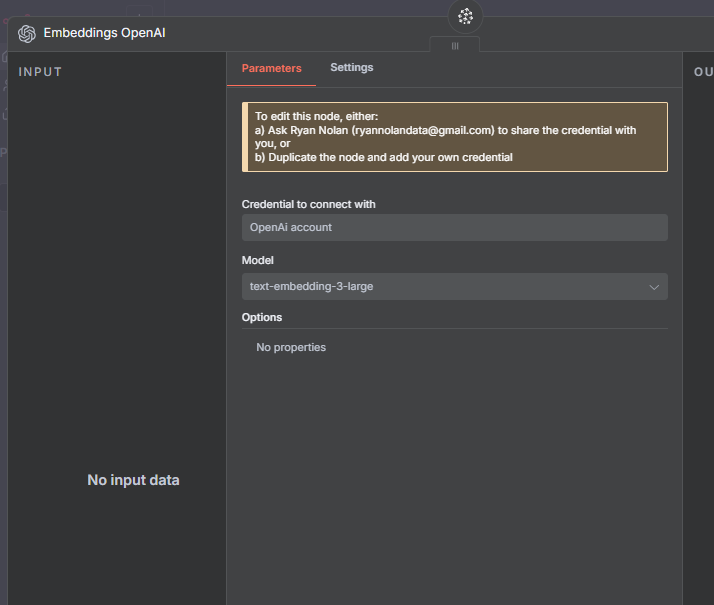
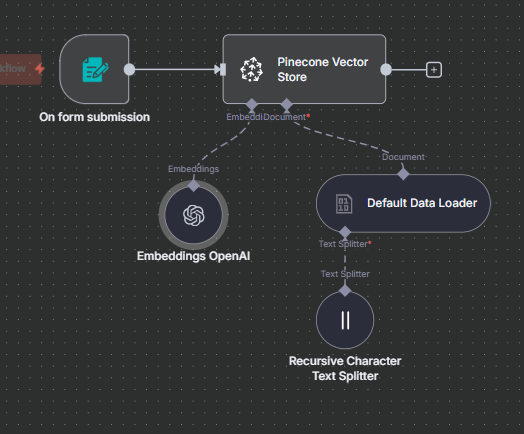
After uploading, you can verify in Pinecone that your index now contains the embedded chunks.
Querying Your Vector Database
Once the data is embedded and stored:
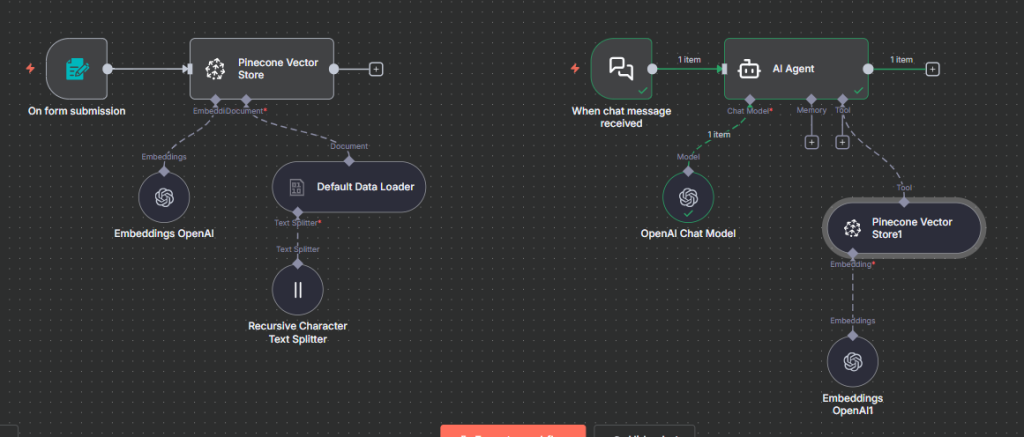
When a user sends a query, you embed that query using the same model.
You send that query vector to Pinecone to retrieve the most similar stored chunks.
The top results (e.g., top 4) are passed to your chat model (like GPT-5 or GPT-4-turbo) as context for generating the final response.
full flow
Final Thoughts
Vector embeddings are the backbone of any RAG system. They allow AI to reason semantically rather than syntactically—understanding meaning instead of just matching words.
Whether you’re building with Pinecone, Weaviate, Chroma, or another vector database, the process remains largely the same:
Chunk → Embed → Store → Query → Retrieve → Generate.
Start with small embeddings if you’re testing, but for any production-grade system—especially one where accuracy matters—large embeddings are the way to go.
Next up: In the following part of this RAG series, we’ll explore metadata management—how to enrich your vector database with contextual information for even more precise retrieval.
Thank you for reading this article. Make sure to check out our other n8n content on the website. If you need any help with n8n workflows we are taking on customers so reach out
