hyperparameter tuning with scikit learn
We would be looking at tuning hyperparameters with Scikit-Learn.
Scikit-Learn is a powerful machine learning library for Python. It provides simple , efficient tools for data analysis and modeling.
Hyperparameter tuning is the process of finding the best values for the settings of a machine learning model that are not learned from data, but set before training.
We start by importing pandas and numpy.
import pandas as pd
import numpy as np
This code generates a synthetic dataset of 500 runners with three features: weekly mileage (Miles_Per_week), farthest distance run (Farthest_run), and whether they qualified for the Boston Marathon (Qualified_Boston_Marathon). The mileage and farthest run values are drawn from normal distributions with defined means and standard deviations, then clipped and rounded to realistic ranges. The qualification label is initially random but set to 1 for runners whose mileage exceeds the average, simulating that higher mileage increases the chance of qualifying. All values are combined into a pandas DataFrame for further analysis or modeling.
mean1 = 55
std_dev1 = 10
num_samples = 500
column1_numbers = np.random.normal(mean1, std_dev1, num_samples)
column1_numbers = np.clip(column1_numbers, 30, 120)
column1_numbers = np.round(column1_numbers).astype(int)
mean2 = 18
std_dev2 = 3
column2_numbers = np.random.normal(mean2, std_dev2, num_samples)
column2_numbers = np.clip(column2_numbers, 12, 26)
column2_numbers = np.round(column2_numbers).astype(int)
column3_numbers = np.random.randint(2, size=num_samples)
column3_numbers[column1_numbers > mean1] = 1
data = {'Miles_Per_week': column1_numbers,
'Farthest_run': column2_numbers,
'Qualified_Boston_Marathon': column3_numbers}
df = pd.DataFrame(data)
Next, we select the first two columns “Miles_Per_week” and “Farthest_run” from the DataFrame df and store it in X.
X = df.iloc[:,0:2]
Then we select the third column “Qualified_Boston_Marathon” fro the DataFrame df and store it in y as the target variable, which is what the model will try to predict.
y = df.iloc[:,2]
Next we import the train_test_split to split our dataset into training and testing sets.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=17, test_size=0.3)
Next we import the RandomForestClassifier from sklearn.ensemble, which is a machine learning model that uses multiple decision trees to make more accurate and stable predictions.
from sklearn.ensemble import RandomForestClassifier
Next we assign the RandomForestClassifier() to rf.
rf = RandomForestClassifier()
Here we define a paramter grid named param_grid for tuning the RandomForestClassifier using methods like GridSearchCV.
This grid will test all combinations of the specified values during hyperparameter tuning.
param_grid = [{
'n_estimators': [500, 1000, 1500],
# 'criterion': ['entropy', 'gini'],
'min_samples_split': [5,10, 15],
'min_samples_leaf': [1, 2, 4]#,
# 'max_depth': [10, 20, 30]
}]
This line imports two tools from sklearn.model_selection:
cross_val_score: Used for evaluating a model using cross-validation to check how well it generalizes.GridSearchCV: Used for automatically testing multiple combinations of hyperparameters (like inparam_grid) to find the best performing model.
from sklearn.model_selection import cross_val_score, GridSearchCV
Here we set up a grid search to find the best hyperparameters for our RandomForestClassifier (rf), using cross-validation.
grid_search = GridSearchCV(rf, param_grid, cv=2, scoring='accuracy', return_train_score = True, n_jobs=-1) #, verbose=10)
Next we start the hyperparameter tuning process using the .fit() method.
We train the model using each combination pf parameters in param_grid.
grid_search.fit(X_train, y_train)
grid_search.best_score_
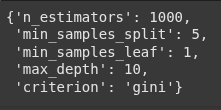
grid_search.best_params_
Randomizedsearchcv
RandomizedSearchCV is a faster alternative to GridSearchCV for hyperparameter tuning.
Instead of trying all possible combinations (like Grid Search), it randomly samples a fixed number of combinations from the parameter grid.
from sklearn.model_selection import RandomizedSearchCV
Next we create random_param_grid, and define hyperparameters that would be randomly sampled by RandomizedSearchCV
random_param_grid = [{
'n_estimators': [500, 1000, 1500],
'criterion': ['entropy', 'gini'],
'min_samples_split': [5, 10, 15],
'min_samples_leaf': [1, 2, 4]#,
# 'max_depth': [10, 20, 30]
}]
random_grid_search = RandomizedSearchCV(rf,
random_param_grid,
cv=5,
scoring='accuracy',
return_train_score = True,
n_jobs=-1,
random_state=17,
n_iter=10)
random_grid_search.fit(X_train, y_train)
random_grid_search.best_score_
random_grid_search.best_params_
Ryan is a Data Scientist at a fintech company, where he focuses on fraud prevention in underwriting and risk. Before that, he worked as a Data Analyst at a tax software company. He holds a degree in Electrical Engineering from UCF.