The Extra Trees Classifier is an ensemble machine learning methid that cimbines predictions from many individual trees.
We import make_classification from sklearn.datasets. module in scikit-learn.
make_classification is a utility function in scikit-learn used to generate synthetic datasets for claasification tasks.
from sklearn.datasets import make_classification
Here, we generate a synthetic classification dataset using the make_classification function and assigns it to X and y.
X is the Numpy array representing the features (input data).
y is the Numpy array representing the target labels i. e the classes our model will try to predict.
n_features=11 specifies that X will have 11 columns
X, y = make_classification(n_features=11, random_state=21)
Here, we import the train_test_split function from the sklearn.model_selection module in scikit-learn.
It is used to split datasets into training and testing subsets.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=16)
Here, we import the ExtraTreesClassifier class from the sklearn.ensemble module in scikit-learn.
from sklearn.ensemble import ExtraTreesClassifier
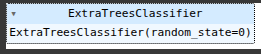
Here we create an instance of the ExtraTreesClassifier model and assign it to the variable ETC
ETC = ExtraTreesClassifier(random_state=0)
This is the training step for our model (ExtraTreesClassifier).
we use the .fit() to train the model.
ETC.fit(X_train, y_train)
from sklearn.model_selection import cross_val_score
Here, we perform cross-validation on our ExtraTreesClassifier model. and we calculate the average accuracy across the folds.
cv=5: This sets the number of folds for cross-validation to 5. The data will be split into 5 equal parts. The model will be trained 5 times, each time using 4 parts for training and 1 part for testing.n_jobs=-1: This parameter tells scikit-learn to use all available CPU cores for parallel processing. This can significantly speed up the cross-validation process, especially for large datasets or computationally intensive models.
cross_val_score(ETC, X_train, y_train, scoring='accuracy', cv=5, n_jobs=-1).mean()
Here, we perform some hyperparameter tuning.
we define a dictionary named param_grid.
This dictionary is used to specify the hyperparamters and their possible values that we want to test when performing hyperparameter tuning.
param_grid = {
'n_estimators' : [100, 300, 500],
'min_samples_leaf': [5,10,25],
'max_features': [2,3,4,6]
}
Here we import GridSearcCV class from the sklearn.model_selection module.
GridSearchCV is a powerful tool used for hyperparameter tuning. It systematically searches through a predefined set of hyperparameter values in our param_grid.
from sklearn.model_selection import GridSearchCV
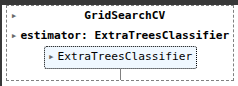
This line initializes a GridSearchCV object, preparing it to perform a systematic search for the best hyperparameters for our ExtraTreesClassifier
ETC2 = GridSearchCV(ETC, param_grid, cv=3, n_jobs=-1)
Then we train using the .fit()
The purpose of training a machine learning model is to teach it to recognize patterns and relationships within a dataset so it can make accurate predictions or decisions on new, unseen data
ETC2.fit(X_train, y_train)
Next we check the best params i.e it tells us the exact combination of parameters that resulted in the highest accuracy.
We also check the best score.
ETC2.best_params_
ETC2.best_score_
