A decision tree is a non-parametric supervised learning algorithm, which is utilized for both classification and regression tasks.
It has hierarchical, tree structure, which consists of a root node, branches, internal nodes and leaf nodes.
note: Parametric supervised learning refers to a type of machine learning where the model assumes a specific functional form and estimates a fixed number of parameters from the training data.
import pandas as pd
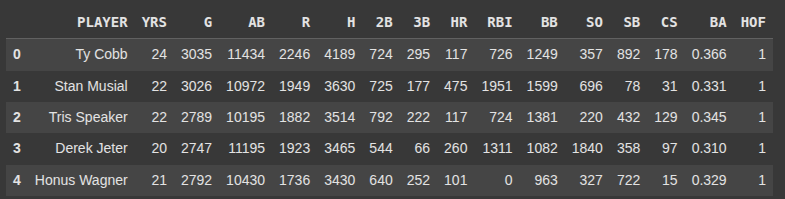
we import pandas as pd, thne we read the csv file called ‘500hits.csv’
Here we select all rows and columns 0 through 12 (not including 13) and assign it to X
X = df.iloc[:, 0:13]
Here we select all rows : from column index 13, and assign it to y
y = df.iloc[:,13]
Next we import train_test_split from sklearn.model_selection
from sklearn.model_selection import train_test_split
Then we split the data into testing and train sets.
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=17, test_size=0.2)
Next we check the snape or dimension of the data, .shape returns (rows, columns)
X_train.shape
X_test.shape
Next we import DecisionTreeClassifier
from sklearn.tree import DecisionTreeClassifier and assign it to the variable "dtc"
dtc = DecisionTreeClassifier()
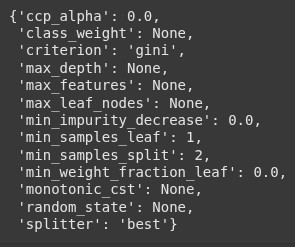
dtc.get_params()
Next we train the model on our data using the .fit()
dtc.fit(X_train, y_train)
Next after traing we predict, i.e we evaluate our models performance using the test data.
y_pred = dtc.predict(X_test)
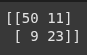
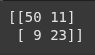
Here, we import the confusion_matrix function from scikit-learn.
It is used to evaluate classification models by comparing the predicted labels with the actual labels.
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test, y_pred))
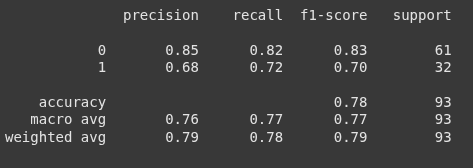
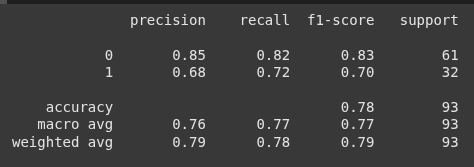
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))
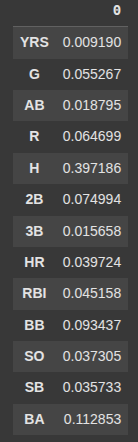
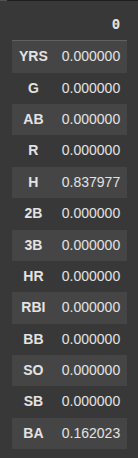
Here we return an array of numbers showing how important each feature was in buiding the decision tree “dtc”
dtc.feature_importances_
features = pd.DataFrame(dtc.feature_importances_, index = X.columns)
features.head(15)
Higher values of ccp_alpha lead to more pruning in the decision tree. This is part of cost-complexity pruning, which removes less important branches to help prevent overfitting.
ccp_alpha(Cost Complexity Pruning Alpha) is a parameter that controls how much the tree should be simplified.
Ryan is a Data Scientist at a fintech company, where he focuses on fraud prevention in underwriting and risk. Before that, he worked as a Data Analyst at a tax software company. He holds a degree in Electrical Engineering from UCF.