import requests
from bs4 import BeautifulSoup
import pandas as pd
import re
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Ultra Running Events</title>
</head>
<body class="site-body">
<header class="site-header">
<h1 class="site-title">Ultra Running Events</h1>
<nav class="main-nav">
<ul class="nav-list">
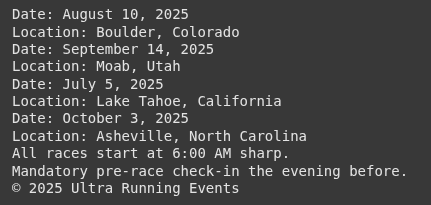
<li><a class="nav-link" href="#races-50">50 Mile Races</a></li>
<li><a class="nav-link" href="#races-100">100 Mile Races</a></li>
</ul>
</nav>
</header>
<section id="races-50" class="race-section race-50">
<h2 class="section-title-50">50 Mile Races</h2>
<ul class="race-list-50">
<li class="race-item">
<h3 class="race-name"><a href="https://www.ryandataraces.com/rocky-mountain-50">Rocky Mountain 50</a></h3>
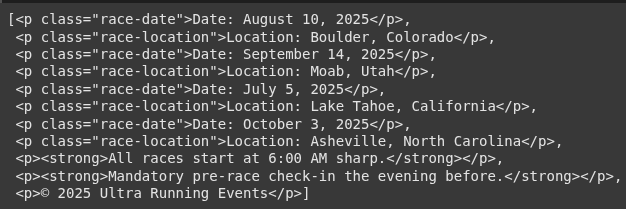
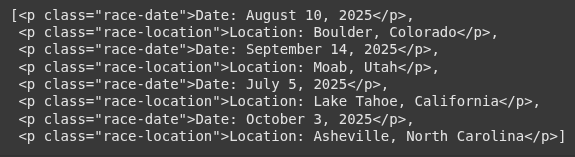
<p class="race-date">Date: August 10, 2025</p>
<p class="race-location">Location: Boulder, Colorado</p>
</li>
<li class="race-item">
<h3 class="race-name"><a href="https://www.ryandataraces.com/desert-dash-50">Desert Dash 50</a></h3>
<p class="race-date">Date: September 14, 2025</p>
<p class="race-location">Location: Moab, Utah</p>
</li>
</ul>
</section>
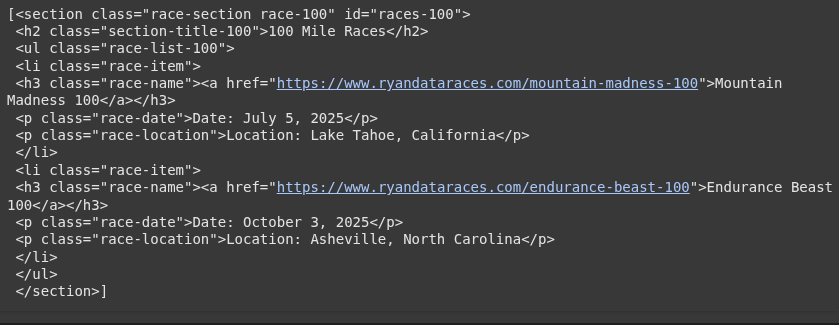
<section id="races-100" class="race-section race-100">
<h2 class="section-title-100">100 Mile Races</h2>
<ul class="race-list-100">
<li class="race-item">
<h3 class="race-name"><a href="https://www.ryandataraces.com/mountain-madness-100">Mountain Madness 100</a></h3>
<p class="race-date">Date: July 5, 2025</p>
<p class="race-location">Location: Lake Tahoe, California</p>
</li>
<li class="race-item">
<h3 class="race-name"><a href="https://www.ryandataraces.com/endurance-beast-100">Endurance Beast 100</a></h3>
<p class="race-date">Date: October 3, 2025</p>
<p class="race-location">Location: Asheville, North Carolina</p>
</li>
</ul>
</section>
<section id="important-notes">
<h2>Important Notes</h2>
<p><strong>All races start at 6:00 AM sharp.</strong></p>
<p><strong>Mandatory pre-race check-in the evening before.</strong></p>
</section>
<footer class="site-footer">
<p>© 2025 Ultra Running Events</p>
</footer>
</body>
</html>
"""
soup_html = BeautifulSoup(html, 'html.parser')
soup_html.select_one('h2')
soup_html.select_one('h2').get_text()
soup_html.select_one('strong').get_text()
soup_html.select('p') #grabs all p tags
soup_html.select('p')[0].get_text()
soup_html.select('p')[1].get_text()
all_p = soup_html.select('p') #grabs all p tags
for p in all_p:
print(p.get_text())
soup_html.select('a')

a_element = soup_html.select('a')
for link in a_element:
print(link['href'])
a_element[2]['href']
soup_html.select('#races-100')
#Example 10 This selector finds any <a> descendant of an <h3> element with the class race-name
#Descendant" means any level deep inside the h3, not just direct children
soup_html.select('h3.race-name a')

#Example 11 Direct Descendents
#Let’s say you want to extract the <a> tag directly under each <h3 class="race-name"> (but only if it's a direct child)
#It will not match nested links.
#Omit > when you want any level of nesting
soup_html.select('h3.race-name > a')

#Example 12 After an Elements Siblings
#Paragraphs after h3 tag
#Have the same parent as an <h3>, and
#Appear after that <h3> in the HTML, regardless of how many elements are in between
#It's useful when you want to grab siblings after a specific element, but not necessarily immediately after
soup_html.select("h3 ~p")
#Example 13 Element in one of two classes (e.g., .race-50 OR .race-100)
sections = soup_html.select('section.race-50, section.race-100')
for section in sections:
title = section.find('h2').text.strip()
print(f"Section Title: {title}")

#Example 14 Element in both classes (e.g., .race-section AND .race-50) (Order doesnt matter)
race50_section = soup_html.select('section.race-section.race-50')
race50_section_v2 = soup_html.select('section.race-50.race-section')
for section in race50_section:
print(f"Found section: {section['id']}")
for section in race50_section_v2:
print(f"Found section: {section['id']}")
URL = "http://books.toscrape.com/"
response = requests.get(URL)
soup = BeautifulSoup(response.text, 'html.parser')
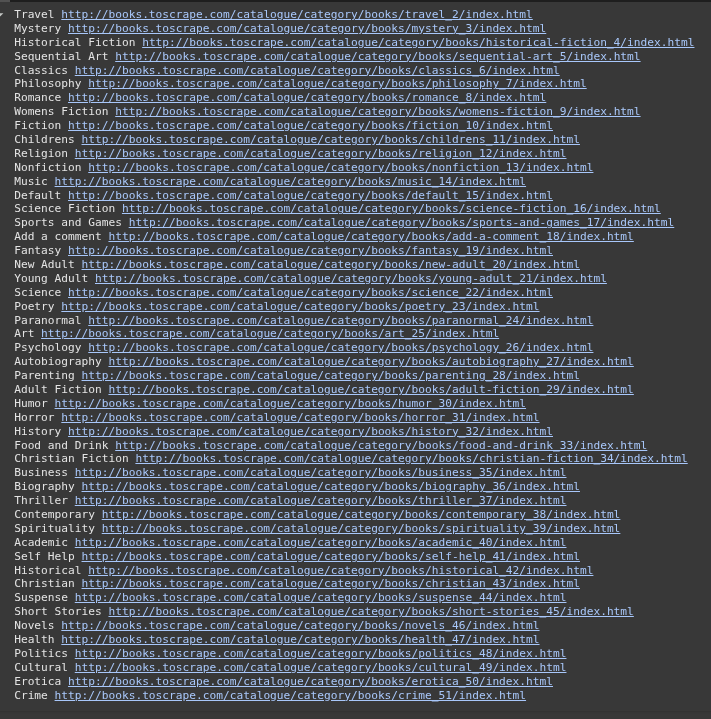
#Example 15 Select category links from sidebar
category_links = soup.select("ul.nav-list ul a")
for a in category_links:
print(a.text.strip(), URL + a['href'])
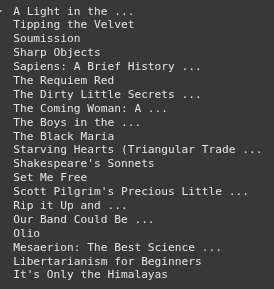
books = soup.select("article.product_pod h3 a")
books

books = soup.select("article.product_pod h3 a")
for book in books:
print(book.get_text())
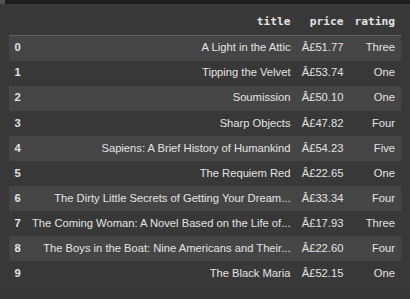
books = soup.select("article.product_pod")
for book in books:
title = book.select_one("h3 a")["title"]
price = book.select_one(".price_color").text
rating = book.select_one("p.star-rating")["class"][-1] # e.g. 'Three'
book_data.append({"title": title, "price": price, "rating": rating})
df = pd.DataFrame(book_data)
df.head(10)
df['price_clean'] = df['price'].str.replace('£', '', regex=False).astype(float)
#Convert GBP to USD (example rate: 1 GBP = 1.0737 USD) (CHECK THIS)
exchange_rate = 1.0737
df['price_usd'] = df['price_clean'] * exchange_rate
df['Price_usd'] = df['price_usd'].apply(lambda x: f"${x:.2f}")
df_five_star = df.loc[df['rating'] == 'Five', ['title', 'Price_usd']]
df_five_star
df_five_star.to_csv('scrapped_book_data.csv')
df_five_star.to_excel('scrapped_book_data.xlsx')
