





https://youtu.be/LbylorwP_ak import requests – Allows us to make HTTP requests to web pages. from bs4 import BeautifulSoup –It is used to parse...
import requests from urllib.parse import urljoin import urllib.robotparser https://ryanandmattdatascience.com/web-scraping-with-python/ Part 1 Getting your first page def response_code(response): if response.status_code == 200: print("Page...
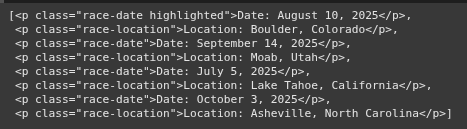
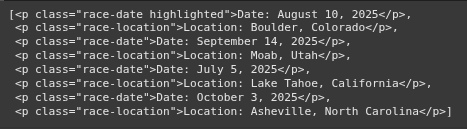
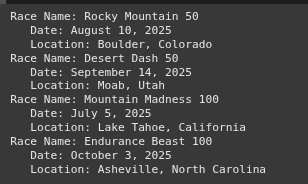
https://youtu.be/EwSwI7b4lWc import requests from bs4 import BeautifulSoup import pandas as pd import re html = """ Ultra Running Events Ultra Running Events...
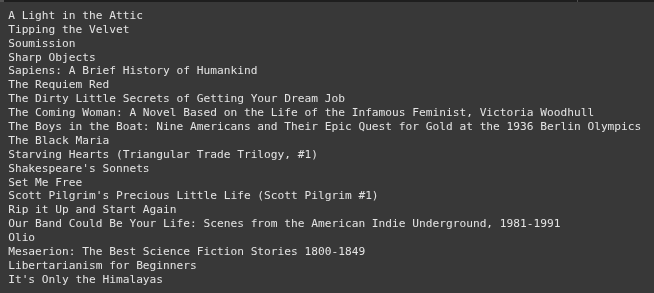
https://youtu.be/sauTLTT0coQ import requests import pandas as pd from bs4 import BeautifulSoup Basic Example HTML Code -> Runners html = """ Personal Running...