adaboost classifier
Adaptive Boosting, or AdaBoost, is a boosting algorithm that combines multiple low-accuracy (weak) models to form a single high-accuracy (strong) model. It works by sequentially training these weak learners, each one focusing more on the errors made by the previous ones. Any machine learning algorithm that supports weighted training samples—such as Decision Trees, Logistic Regression, or Support Vector Machines (SVMs)—can be used as a base estimator in AdaBoost. Additionally, the performance of the model can be further improved through hyperparameter tuning.
We start by importing pandas as pd
import pandas as pd
Next we import make_classification from sklearn.datasets.
from sklearn.datasets import make_classification.
It is a utility function that generates a synthetic classification dataset, commonly used for testing or demonstrating machine learning models
n_samples=2000: Generates 2000 rows of data.n_features=10: Each sample has 10 total features.n_informative=8: 8 features are informative (i.e., actually help determine the target class).n_redundant=2: 2 features are redundant (linear combinations of the informative ones).random_state=11: Ensures reproducibility by setting a seed for random number generation.
X, y = make_classification(n_samples=2000, n_features=10, n_informative=8, n_redundant=2, random_state=11)
Next we import train_test_split from sklearn.model_selection.
We use this to split our data into training and testing sets.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=11)
By default, if no base estimator is specified, AdaBoost uses a DecisionTreeClassifier with max_depth as the weak learner
from sklearn.ensemble import AdaBoostClassifier.
An AdaBoost classifier is a meta-estimator that begins by fitting a classifier on the original dataset and then fits additional copies of the classifier on the same dataset but where the weights of incorrectly classified instances are adjusted such that subsequent classifiers focus more on difficult cases.
Next we assign it to abc.
abc = AdaBoostClassifier()
Next we train the AdaBoostClassifier() on the dataset using the .fit() method
abc.fit(X_train, y_train)
Next we make predictions with our trained model on the test data set using the .predict()
y_pred = abc.predict(X_test)
accuracy_score measures the ratio of correctly predicted samples to the total number of samples.
confusion_matrix creates a matrix showing actual vs predicted classifications.
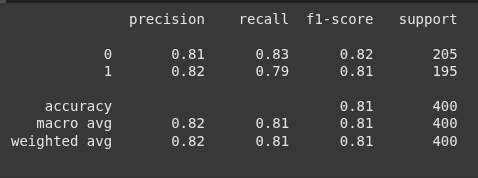
classifcation_report returns precision, recall, F1-score, and support for each class.
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
print(accuracy_score(y_test, y_pred))
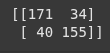
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
Next we use a different model “LogisticRegression”.
from sklearn.linear_model import LogisticRegression
abclog = AdaBoostClassifier(estimator=LogisticRegression())
Next we also train using the .fit() method.
abclog.fit(X_train, y_train)
Then we predict using the .predict()
y_pred2 = abclog.predict(X_test)
print(accuracy_score(y_test, y_pred2))
Next, we look at Support Vector Machine.
A Support Vector Machine (SVM) is a powerful supervised machine learning algorithm used for both classification and regression tasks, but it is especially popular for binary classification.
from sklearn.svm import SVC
svc=SVC(kernel='linear', probability=True, )
abcsvm =AdaBoostClassifier(estimator=svc,n_estimators=25, learning_rate=0.1)
Then once again, we train the model using our dataset.
abcsvm.fit(X_train, y_train)
Next we make predictions using the text data
y_pred3 = abcsvm.predict(X_test)
print(accuracy_score(y_test, y_pred3))
Next we look at hyperparameter tuning,
There is a trade-off between the learning_rate and n_estimators hyperparameters during tuning. Reducing the learning_rate typically requires increasing the number of estimators (n_estimators) to maintain performance, while increasing the learning rate may allow for fewer estimators but can risk overfitting or instability.
parameters = {
'n_estimators': [1, 5, 10, 50, 100, 500],
'learning_rate': [0.0001, 0.001, 0.01, 0.1, 1.0]
}
GridSearchCV performs an exhaustive search over a specified set of hyperparameter values for an estimator (e.g., SVM, Random Forest, AdaBoost) using cross-validation. It helps find the best combination of parameters to optimize model performance.
from sklearn.model_selection import GridSearchCV
abc2 = GridSearchCV(abc, parameters, cv=5, n_jobs=-1)
Once again we train our mdoel.
abc2.fit(X_train, y_train)
Next we get the best params and best score
abc2.best_params_
abc2.best_score_
Here, we assign AdaBoostClassifier to abc3, this tie with just the learning rate and numbe rof estimators.
abc3 = AdaBoostClassifier(learning_rate=0.1, n_estimators=500)
Then we train trhe model on the dataset.
abc3.fit(X_train, y_train)

Then we make predictions using the test dataset.
y_pred4 = abc3.predict(X_test)
print(accuracy_score(y_test, y_pred4))
Ryan is a Data Scientist at a fintech company, where he focuses on fraud prevention in underwriting and risk. Before that, he worked as a Data Analyst at a tax software company. He holds a degree in Electrical Engineering from UCF.