Retrieval-Augmented Generation (RAG) is one of the most powerful techniques for building intelligent, context-aware AI applications. One of the earliest and most crucial steps in a RAG pipeline is chunking, i.e splitting large documents into smaller, digestible pieces so they can be efficiently processed, embedded, and stored in a vector database.
This article explains how chunking works, why it’s essential, and how to implement different text-splitting strategies in n8n using Pinecone as the vector database and OpenAI embeddings for encoding the text.
Before we start, if you are looking for help with a n8n project, we are taking on customers. Head over to our n8n Automation Engineer page.
What Is Chunking and Why Do We Need It?
Large Language Models (LLMs) have context limits,
they can only process a certain number of tokens at once. Feeding a model an entire book or document would be inefficient and often impossible. Instead, we split the document into smaller chunks.
Each chunk represents a self-contained piece of information that can be independently embedded and retrieved later. When the model receives a query, we only send the most relevant chunks rather than the entire dataset.
Chunking helps:
Improve retrieval accuracy
Reduce costs
Maintain contextual coherence
Increase flexibility in combining multiple data sources
Text Splitters in N8N
In n8n, you can implement chunking through text splitters.
Text splitters break down documents based on:
Characters
Tokens
Recursive structures (paragraphs, sentences, etc.)
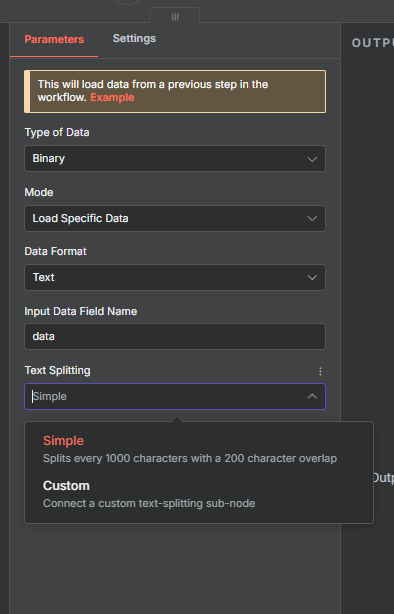
n8n provides both a default data loader (simple splitter) and custom text splitters. You can choose either depending on your workflow’s complexity.
Two Integration Options:
Default Data Loader: This uses a built-in, simple character-based chunking strategy.
Custom Text Splitter : This allows you to define exactly how your text is split (character, token, or recursive methods).
Join Our AI Community
Key Chunking Parameters
Before diving into examples, let’s clarify three crucial parameters used across all splitter types:
Separator : Defines where to split. Common separators include:
Periods (
.)Newlines (
\n)Dashes (
-)Or any custom character(s)
Chunk Size : The number of characters or tokens in each chunk.
Typical range: 500–1,000 characters (or similar in tokens).Chunk Overlap : The number of characters or tokens repeated between consecutive chunks.
Overlap ensures contextual continuity, so chunks don’t lose meaning when split.
Chunk 1: Artificial intelligence is transforming industries.
Chunk 2: Transforming industries, machine learning is a subset of AI.
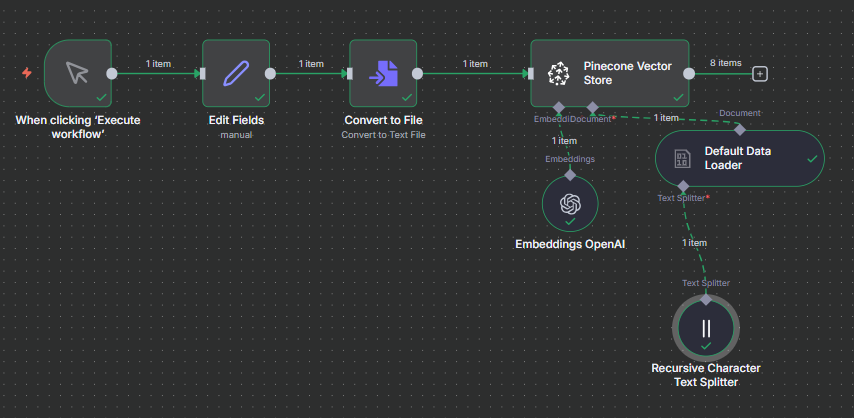
Step-by-Step Setup Using N8N + Pinecone
To demonstrate how this works, let’s walk through a complete setup where we’ll process text (for example, extracted from the back of Christy Mathewson baseball cards) and store it in Pinecone after splitting.

Configure Pinecone in N8N
Open the Pinecone Vector Store node.
Paste in your API key under “API Credentials.”
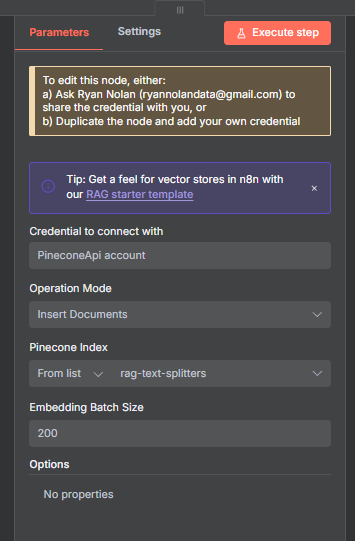
Create an Index
Example configuration:
Name: rag_text_splitters
Model: text-embedding-3-large
Dimension: 3072
Metric: cosine
Environment: AWS (us-east-1)
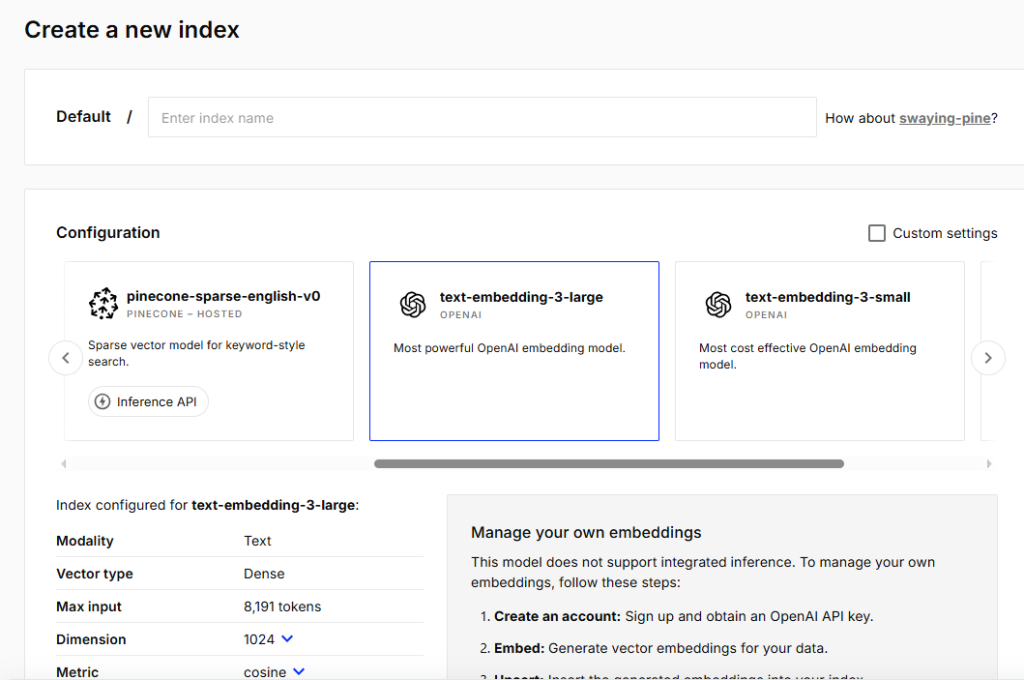
Once created, confirm your index is live and connected.
Connecting OpenAI Embeddings
Since we’ll use OpenAI embeddings to transform text into vectors:
Get your OpenAI API key.
In N8N, configure:
Provider:
OpenAIModel:
text-embedding-3-largeBatch size: Default (200)
These embeddings will be stored inside Pinecone as part of each document chunk.

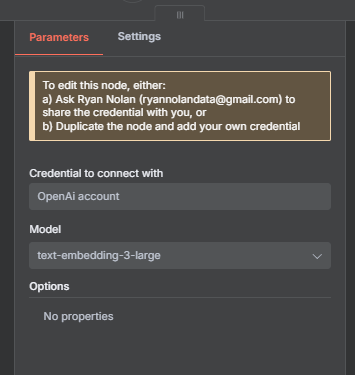
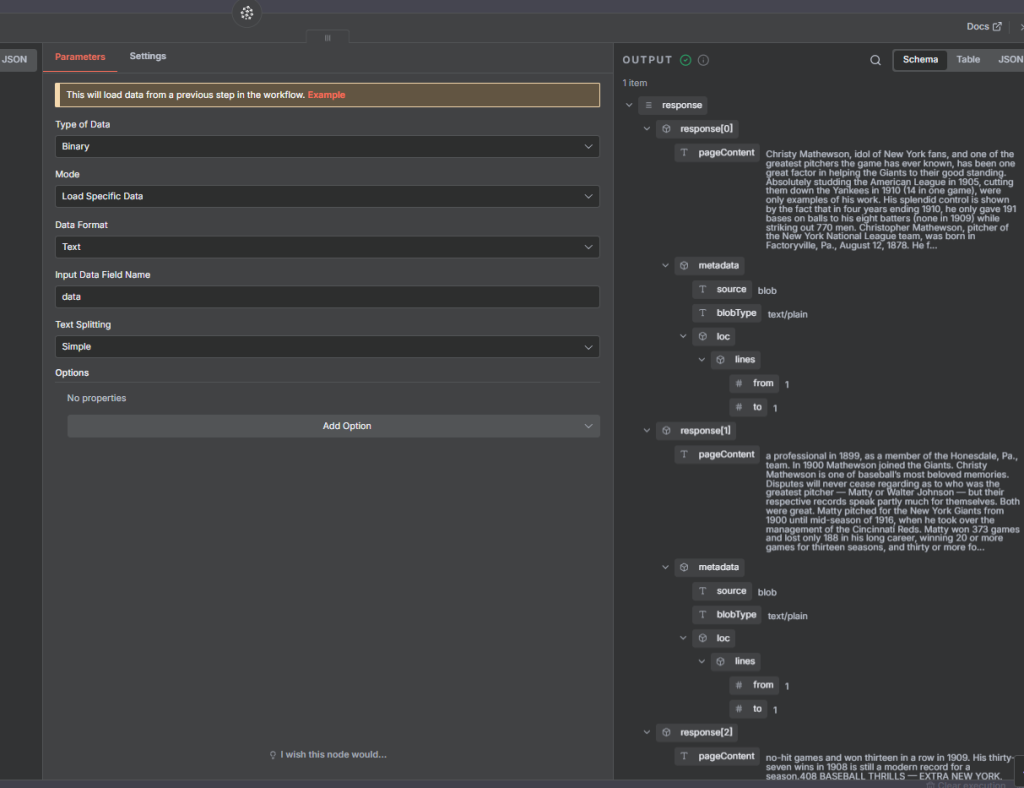
Loading Text Data into NaN
Inside N8N:
Use the Edit Fields node to input your text.
Connect it to a Convert to File node (format:
.txt).Link this file to the Pinecone Vector Store node using the Default or Custom Text Splitter.
This creates a smooth data flow:
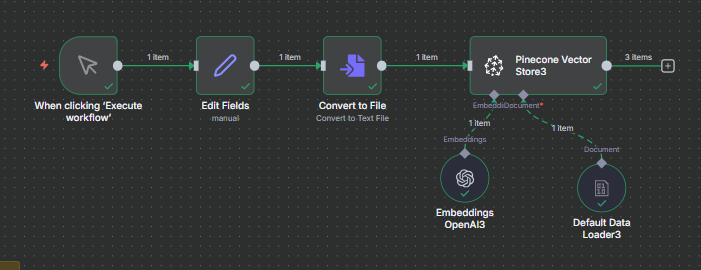
Exploring the Text Splitter Options
Now that Pinecone and embeddings are set up, let’s look at the four text splitter options you can use in N8N.
1. Default (Simple) Text Splitter
How it works:
Splits text into 1,000-character chunks
Adds a 200-character overlap
This default setup is built directly into NaN’s data loader. It’s perfect for quick testing.
Full flow
output
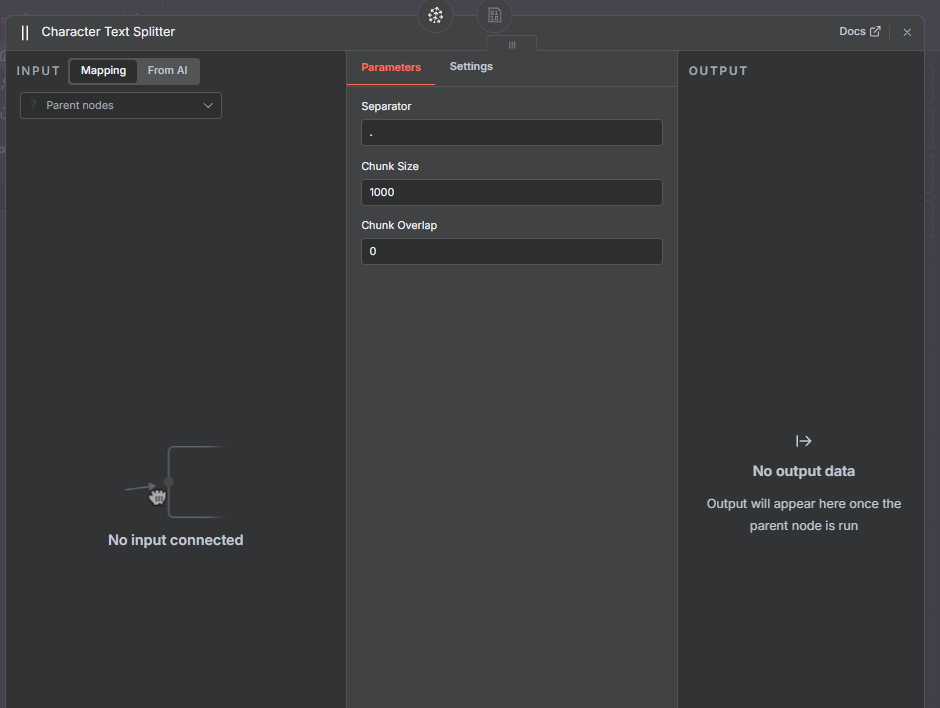
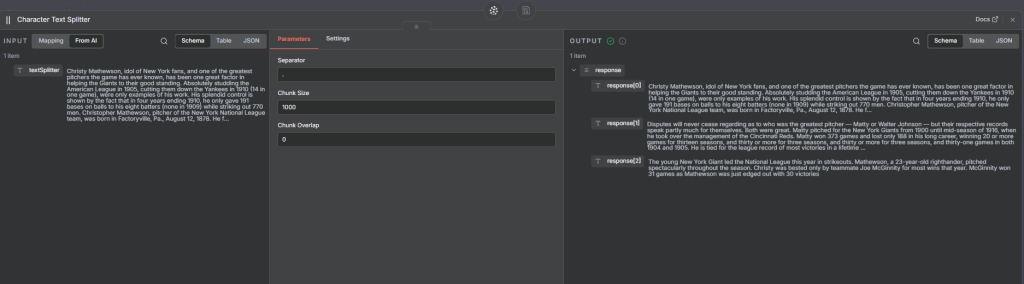
2. Character Text Splitter
How it works:
Splits the text based on a specific character separator, such as a period (.).
Example Settings:
Separator: "."
Chunk size: 1,000
Chunk overlap: 0
Each sentence becomes its own chunk or part of a chunk. When stored in Pinecone, each record corresponds to one of these character-based splits.
Use Case:
When your data has clear punctuation or structural patterns.
Full flow
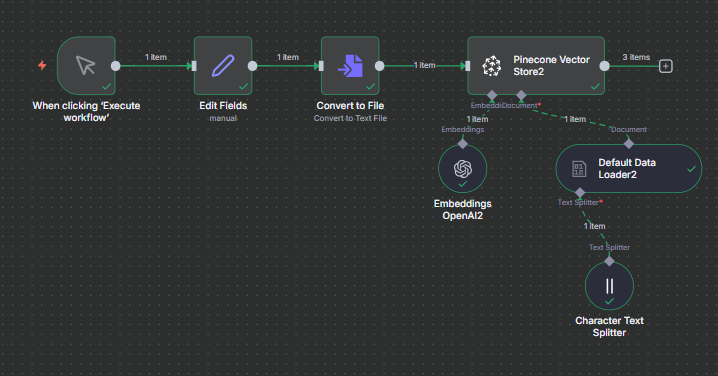
output
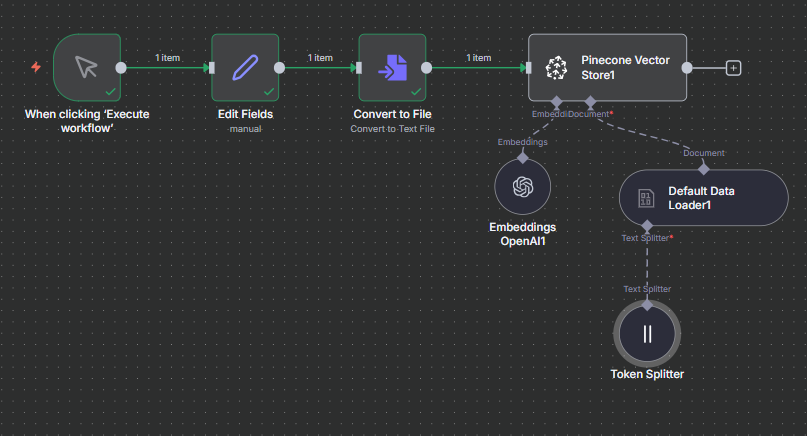
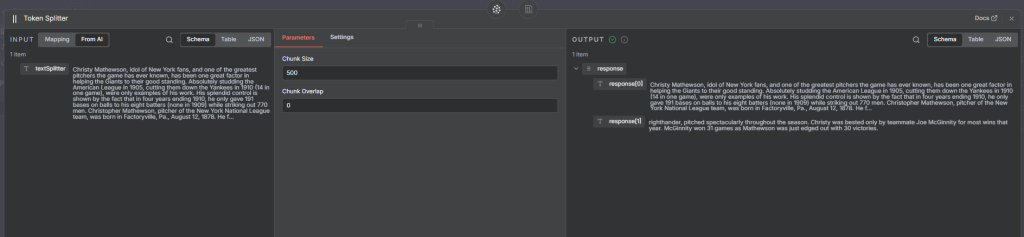
3. Token Text Splitter
How it works:
Splits text based on tokens, not characters.
This aligns closely with how OpenAI models interpret input.
Example Settings:
Chunk size: 500 tokens
Chunk overlap: 0
Example:
If your text is 550 tokens long, NaN will generate two chunks (500 + 50 tokens) and send each for embedding before saving to Pinecone.
Why it’s useful:
Token-level control ensures consistent input size for language models.
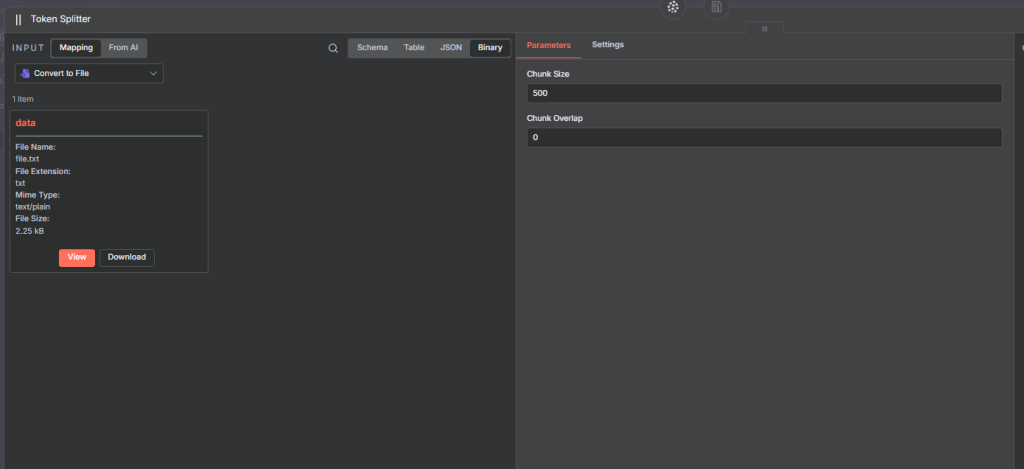
Full flow
output
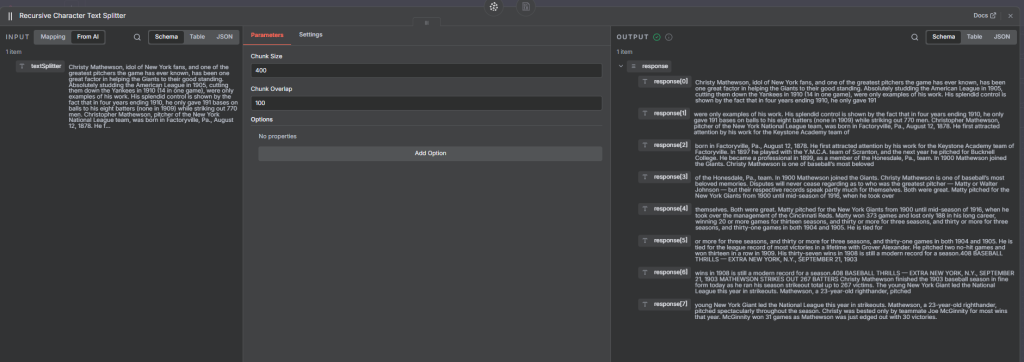
4. Recursive Character Text Splitter (Recommended)
How it works:
The Recursive Text Splitter attempts to maintain natural text boundaries , paragraphs, sentences, and words for more meaningful chunks.
Example Settings:
Chunk size: 400
Chunk overlap: 100
This splitter tries to keep related text together and avoids splitting in the middle of sentences. Even though it’s character-based, it “recursively” backs off from large to smaller units when splitting.
Once processed, the resulting chunks , typically 6–10 in this example are embedded and stored in Pinecone.
Why it’s recommended:
It yields semantically coherent chunks, ideal for high-quality RAG retrieval
Full flow
How Data Looks Inside Pinecone
After processing, you can inspect your Pinecone index to confirm that:
Each chunk of text is stored as an individual vector entry.
Each entry includes:
The chunk text
Its vector embedding
Optional metadata (source, page number, etc.)
You’ll see a list of chunks (e.g., 3, 8, or more depending on your settings), each searchable via cosine similarity when you run a query.
Final thought
By combining N8N’s text splitters with OpenAI embeddings and Pinecone’s vector storage, you can create a robust, scalable RAG pipeline capable of handling complex, multi-document retrieval tasks.
Thank you for reading this article. Make sure to check out our other n8n content on the website. If you need any help with n8n workflows we are taking on customers so reach out
