Boosting in machine learning is a technique that combines multiple simple models, often decision trees into a single, stronger model.
It works with regression trees and improves performance by sequentially learning from the mistakes of previous models.
According to the scikit-learn documentation, at each stage, a regression tree is fit on the negative gradient of the loss function, essentially allowing the model to focus on the erros made in earlier iterations.
This progressive refinement helps improve accuracy, but it can also lead to overfitting if not carefully managed.
we start by importing dataset from sklearn.
Then we load the load_diabetes()
from sklearn import datasets
diabetes = datasets.load_diabetes()
X represents the features (input variable) of the dataset.
y represents the target( output variable), which in this case is a quantitative measure of disease progression.
X = diabetes.data
y = diabetes.target
X
y

Next we import the train_test_split from sklearn.model_selection so we can spilt the data into training and testing.
we use the training data to train the model and we use the testing data to evalaute te model after training.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=17)
Next we import Gradient Boosting Regressor from scikit-learn, which is a powerful machine learning model used for regression tasks.
from sklearn.ensemble import GradientBoostingRegressor
Here we create assign a variable “gbr” to the GradientVoostingRegressor(), then we train the model on the X_train and y_train data.
we use the .fit() method to train the model.
gbr = GradientBoostingRegressor()
gbr.fit(X_train, y_train)
Next, we use the gbr to make predictions on the test data X_test.
y_pred = gbr.predict(X_test)
Next, we import three of the commonly used evaluation metrics for regression models.
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
mean_absolute_error mesures the average absolute difference between predicted and actual values.
lower value is better value
mean_absolute_error(y_test, y_pred)
mean_squared_error measures the average of the squares of the errors
It penalizes larger errors more that mean abosulte error (mae)
mean_squared_error(y_test, y_pred)
Aso called the coefficient of determination, indicates how well the model explains the variabilty of the target.
The values ranges from negative infinity to 1.
r2_score(y_test, y_pred)
Here we are defining hyperparameters grid for tuning the GradientBoostingRegressor.
hyperparameters are configuration seetings used to control the learning process of a machine learning model.
The are usually set before training and affect how the models learn.
param_grid = {
'n_estimators': [100, 200, 300],
'learning_rate': [0.01, 0.1, 0.2],
'max_depth': [3, 4, 5],
'min_samples_split': [2, 3, 4],
'min_samples_leaf': [1, 2, 3],
'criterion': ['squared_error'] # Changed 'mse' to ['squared_error'] as 'mse' is deprecated in scikit-learn 1.0 and removed in 1.2
}
We import GridSearchCV to automatically find the best combination of hyperparameters for the model.
from sklearn.model_selection import GridSearchCV
gbr_cv = GridSearchCV(estimator=gbr, param_grid=param_grid, cv=3, n_jobs=-1, scoring='neg_mean_squared_error')
We train the model using the .fit()
gbr_cv.fit(X_train, y_train)
we make preictions using .predict()
y_pred = gbr_cv.predict(X_test)
Next, we evalaute the model same as before.
mean_absolute_error(y_test, y_pred)
mean_squared_error(y_test, y_pred)
r2_score(y_test, y_pred)
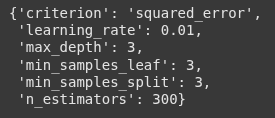
we use .best_params_ to get the best parameters for the model.
gbr_cv.best_params_